%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23a5d028;%20}%20.st1%20{%20fill:%20%23fff;%20}%20.st2%20{%20fill:%20%231de2db;%20}%20.st3%20{%20fill:%20%2341bdf9;%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='logo-unaice-line'%3e%3cpath%20class='st1'%20d='M143.3,36.1c-1.2,0-2.1-.9-2.1-2.1V12.2c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,1.2-.9,2.1-2.1,2.1ZM143.2,6.2c-1.3,0-2.4-1-2.4-2.4v-.8c0-1.3,1-2.4,2.4-2.4s2.4,1.1,2.4,2.4v.8c0,1.3-1.1,2.4-2.4,2.4Z'/%3e%3cpath%20class='st3'%20d='M23.7,36.1H2c-.5,0-1-.4-1-1V2.3c0-.5.4-1,1-1h21.7c.5,0,1,.4,1,1v32.9c0,.5-.4,1-1,1'/%3e%3cpath%20class='st2'%20d='M41.8,36.1h-14.4c-.5,0-1-.4-1-1v-14.5c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.5c0,.5-.4,1-1,1'/%3e%3cpath%20class='st0'%20d='M41.8,17.9h-14.4c-.5,0-1-.4-1-1V2.2c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.7c0,.5-.4,1-1,1'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M196.4,29.2c-2.1,2.1-3.6,3.2-7.1,3.2s-7.4-2.3-8.2-7.4h16.7c2.7,0,2.9-1.9,2.7-4-.7-6.2-5.3-11.2-11.6-11.2s-12.3,5.1-12.3,13.4,5.4,13.3,12.6,13.3,8.3-2.6,10-4.3c1.8-2.1-1.2-4.7-2.8-3ZM188.9,13.7c4.7,0,7.3,4.1,7.6,7.3h-15.3c.7-4.3,3.4-7.3,7.7-7.3Z'/%3e%3cpath%20class='st1'%20d='M132.1,12.9c-1.9-1.9-5.4-2.9-8.2-2.9s-5.3.5-8.2,1.8c-2.4,1-.9,5,1.6,3.7,2.1-1,3.3-1.5,6.3-1.5s6.7,1.1,6.8,6.1c-1.8-.5-2.7-.8-6.9-.8-6.8,0-11.3,3.3-11.3,8.8s4.1,8.4,10.1,8.4,5.4-.6,8.3-2.9v.5c0,2.8,4.2,2.6,4.2,0v-13.8c0-3.1-.8-5.5-2.7-7.4ZM130.4,26.2c0,3.6-3.4,6.3-8,6.3s-5.9-1.7-5.9-4.6,2.5-4.6,6.8-4.6c0,0,4.8,0,7.1,1v1.9Z'/%3e%3cpath%20class='st1'%20d='M80,36.1c-1.2,0-2.1-.9-2.1-2.1V3.4c0-1.2,1-2.2,2.2-2.2h.4c.8,0,1.4.4,2,1.1l20.2,25.7V3.4c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v30.7c0,1.1-.5,2-1.9,2s-1.9-.8-2.2-1.2l-20.7-26.2v25.3c0,1.2-.9,2.1-2.1,2.1Z'/%3e%3cpath%20class='st1'%20d='M60.2,36.5c-5.1,0-10.5-4.3-10.5-10.7v-13.5c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v13.1c0,4.5,2.5,7.1,6.6,7.1s7.3-3.2,7.3-7.5v-12.7c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,2.8-4.2,2.7-4.2,0v-.5c-1.5,1.6-3.3,2.9-7.6,2.9Z'/%3e%3cpath%20class='st1'%20d='M163.8,36.5c-7.1,0-13.1-6-13.1-13.3s4.8-13.5,13.5-13.5c4.4,0,6.9,2,8.8,3.7,1.8,1.5-.8,5.1-2.8,3.3-.8-.8-3.3-3-6.4-3-4.8,0-8.6,4-8.6,9.2s3.8,9.3,8.6,9.4c3.7,0,4.9-1,7-3.1,1.6-1.8,4.6,1,3,2.8-3,3-5.7,4.5-10,4.5h0Z'/%3e%3c/svg%3e)
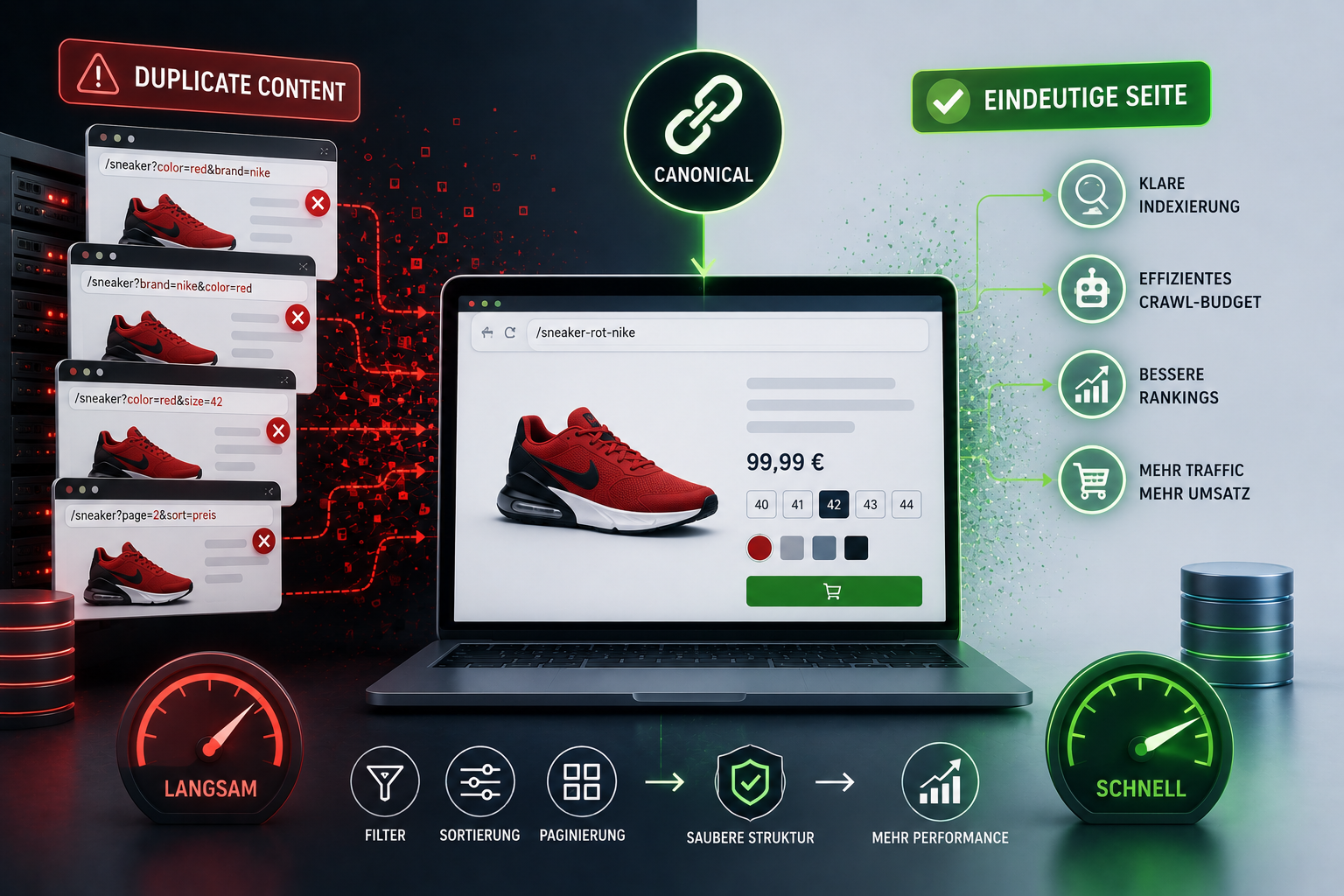
Stell dir eine riesige Bibliothek vor, in der exakt das gleiche Buch unter dutzenden verschiedenen Titeln im Regal steht. Das verwirrt nicht nur den Bibliothekar, sondern auch jeden Besucher, der nach dem Original sucht. Im E-Commerce passiert genau das täglich: Durch ungesteuerte Filter, Sortierfunktionen und Paginierungen entstehen unzählige URLs mit identischem Inhalt. Suchmaschinen wissen nicht mehr, welche Version relevant ist.
Viele E-Commerce Manager investieren massiv in neue Shop-Systeme, verlieren aber durch technische Unsauberkeiten wertvolle Sichtbarkeit. Die manuelle Pflege dieser URLs wird schnell zur endlosen Excel-Schlacht. In unserer Praxis sehen wir oft, dass genau dieser technische Flaschenhals das Wachstum ausbremst. Wir zeigen dir, wie du diese Strukturprobleme an der Wurzel packst und dein Datenkapital effizient nutzbar machst.
Technische Grundlagen: Wie du Duplicate Content bei Produkt-Filtern vermeidest
Duplicate Content bezeichnet identische oder sehr ähnliche Inhalte, die über verschiedene URLs erreichbar sind und Suchmaschinen bei der Indexierung massiv verwirren. Laut einer Analyse von weventure (2025) entstehen diese Duplikate bei wachsenden Online-Shops oft unbemerkt. Die Hauptursachen sind technische Faktoren wie URL-Parameter, falsch gesetzte Canonical-Tags oder fehlende Content-Strategien bei der Produktpflege.
Ein klassisches Praxisbeispiel veranschaulicht das Problem: Ein Shop für Sneaker bietet Filter für Größe, Farbe und Marke an. Klickt ein Nutzer die Filter an, erzeugt das System URLs wie ?color=red&brand=nike und ?brand=nike&color=red. Obwohl beide Seiten exakt den selben Schuh zeigen, erscheinen sie für den Google-Bot wie zwei völlig verschiedene Webseiten. Ohne eine gezielte Parameter-Steuerung indexiert die Suchmaschine beide Varianten, was die Relevanz der eigentlichen Hauptseite drastisch schwächt.
Die fatalen Folgen für Crawl-Budget und Rankings
Ein ungesteuerter Duplicate Content durch Filter-Seiten reduziert den organischen Traffic eines Online-Shops um durchschnittlich 20 bis 40 Prozent. Zu diesem alarmierenden Ergebnis kommt eine aktuelle Auswertung von Erock Marketing (2026). Das Hauptproblem liegt in der massiven Verschwendung des Crawl-Budgets. Der Google-Bot verzettelt sich regelrecht im Auslesen hunderter irrelevanter Parameter-URLs, wodurch neue oder aktualisierte Produkte oft erst mit großer Verzögerung im Index landen.
Zusätzlich warnt SEO-Expertin Kathrin Landsdorfer (2025) vor einer stark verwässerten Link-Autorität. Wenn externe Backlinks oder interne Verweise auf verschiedene Filter-Varianten streuen, bündelt sich die Ranking-Power nicht mehr auf der Hauptkategorie. Im schlimmsten Fall verdrängen irrelevante Filter-Seiten deine strategisch wichtigen Kategorieseiten aus den Suchergebnissen. Eine saubere URL-Struktur und konsequente interne Verlinkung auf die kanonische Version sind daher absolute Pflichtaufgaben.
Wie steuerst du Parameter-URLs in der Google Search Console richtig?
Die Google Search Console bietet ein spezielles Tool zur Parameterverwaltung, das Suchmaschinen präzise Anweisungen zum Umgang mit dynamischen Filter-URLs liefert. Wie die Experten von SISTRIX (2025) betonen, ist diese Funktion für Websites mit umfangreichen Sortierfunktionen unerlässlich. Du kannst Google hier exakt mitteilen, welche Parameter den eigentlichen Seiteninhalt verändern und welche lediglich die Reihenfolge der Produkte anpassen.
Definiere beispielsweise den Parameter „sortierung=preis“ mit der Eigenschaft „;ändert Seiteninhalt nicht“, weiß der Crawler sofort Bescheid. Er ignoriert diese spezifischen Varianten bei der Indexierung und spart wertvolle Ressourcen. Die korrekte Konfiguration in der Search Console ist der erste und wichtigste Schritt, um die Qualität deines Index zu schützen und technische SEO-Probleme proaktiv zu verhindern.
Best Practices für das Parameter-Handling
Ein effektives Parameter-Handling besteht aus der strategischen Indexierung relevanter Filter und dem gezielten Ausschluss unwichtiger Kombinationen durch Noindex-Tags. Die SEO-Spezialisten von Erock Marketing (2026) warnen ausdrücklich davor, Filter-URLs pauschal indexieren zu lassen. Dies führt unweigerlich zu einer massiven Index-Aufblähung ohne jeglichen Mehrwert für den Nutzer.
Die wichtigsten Best Practices umfassen:
Möchtest du wissen, wie du diese Prozesse in deinem Unternehmen automatisieren kannst? Sprich uns für eine unverbindliche Potenzialanalyse an.
Welche Rolle spielen Canonical-Tags bei der Filter-Bereinigung?
Ein Canonical-Tag ist ein HTML-Element im Quellcode, das Suchmaschinen eindeutig auf die bevorzugte Originalversion einer Webseite hinweist. Bei der Nutzung von Facettensuchen und Produktvarianten ist dieses Tag ein unverzichtbares Werkzeug zur Fehlervermeidung. Weventure (2025) empfiehlt dringend, verschiedene Farben, Größen oder Ausführungen eines Artikels immer mit einem Canonical-Tag auf die Hauptversion verweisen zu lassen.
Alternativ kannst du diese Varianten als konfigurierbares Produkt auf einer einzigen URL zusammenführen. Das beugt nicht nur internen Inkonsistenzen vor, sondern bündelt auch die gesamte Ranking-Power auf einer starken Seite. Strukturierte Daten und korrekte Markups für Produkte oder Bewertungen helfen Suchmaschinen zusätzlich, die Inhalte fehlerfrei zu interpretieren – selbst wenn optisch ähnliche Varianten im Shop existieren.
Wie löst du Near Duplicate Content bei Produktvarianten auf?
Near Duplicate Content bezeichnet inhaltlich nur leicht veränderte Webseiten, die sich oft nur durch wenige spezifische Attribute wie Farbe, Gewicht oder Größe unterscheiden. Kathrin Landsdorfer (2025) illustriert dies an einem treffenden Beispiel: Ein Shop verkauft eine Himbeerkernöl-Seife und eine Neemöl-Seife. Beide basieren auf den gleichen Grundzutaten wie Kokosöl und nutzen standardisierte Herstellertexte. Da Form, Preis und Basis identisch sind, stuft Google die Seiten als Duplikate ein.
Solche identischen Texte, die E-Commerce-Betreiber häufig unreflektiert vom Hersteller oder von Marktplätzen übernehmen, schaden der Sichtbarkeit enorm. Der Marktplatz gewinnt aufgrund seiner höheren Domain-Autorität fast immer das Ranking-Duell. Die Content-Strategie von uNaice versieht jede Produktvariante mit individuellen Beschreibungen zur inhaltlichen Abgrenzung vom Wettbewerb.
Automatisierte Content-Erstellung durch KI und Ontologien
Die Software DataNaicer ermöglicht die vollautomatische Aufbereitung von Produktdaten, um tausende einzigartige Texte ohne manuellen Aufwand zu generieren. Im Gegensatz zu herkömmlicher Blackbox-KI nutzen wir intelligente Ontologien. Diese Wissensgraphen verstehen die logischen Zusammenhänge deiner Artikel und würfeln nicht einfach nur Textbausteine durcheinander. So lösen wir den „Flaschenhals Mensch“ in der Datenpflege auf.
Unsere Lösung bietet folgende zentrale Vorteile:
Da wir eine Flatrate ohne Kosten pro SKU anbieten, skaliert das System problemlos von 10.000 bis auf 5 Millionen Datensätze. Du kannst deinen Shop in über 40 Sprachen internationalisieren, ohne neues Personal einstellen zu müssen.
Fazit: Stammdaten-Perfektion als Ranking-Faktor
Die Vermeidung von doppelten Inhalten bei Filter-URLs ist keine optionale Fleißaufgabe, sondern das technische Fundament für deinen E-Commerce-Erfolg. Ungesteuerte Parameter verschwenden dein Crawl-Budget, verwässern deine Link-Autorität und kosten dich bis zu 40 Prozent deines organischen Traffics. Durch den gezielten Einsatz von Canonical-Tags, Noindex-Anweisungen und der Search Console lenkst du Suchmaschinen präzise auf deine wichtigsten Seiten.
Doch die technische Struktur ist nur die halbe Miete. Echtes Datenkapital entsteht erst, wenn deine Produktvarianten mit einzigartigen, fehlerfreien Inhalten glänzen. Manuelle Excel-Tabellen stoßen hier schnell an ihre Grenzen. Mit der richtigen technologischen Unterstützung befreist du dein Team von repetitiven Aufgaben und skalierst deine Sichtbarkeit auf Knopfdruck.
Löse jetzt die Handbremse in deiner Datenpflege. Buche ein kostenloses Erstgespräch oder teste unsere Qualität direkt an deinen eigenen Daten mit unserem unverbindlichen 100-Datensätze-Test. Lass uns gemeinsam deine individuelle Qualitäts-Pipeline aufbauen.
Häufig gestellte Fragen
Bereit für den nächsten Schritt?
Kontaktiere uns für eine unverbindliche Beratung zu deinem Datenprojekt.
Jetzt Kontakt aufnehmenQuellen
