
100 % Datenintegrität
99 % automatisiert
Profitiere mit uns,
wo andere teuer scheitern
Selbst unsaubere und unvollständige Datenquellen werden mit uns zu perfekten Stammdaten. In Minuten statt Stunden dank KI – und trotzdem fehlerfrei.
Versprechen viele? Wir beweisen es dir!
Diese Marktführer vertrauen auf unsere Daten-Lösung:
 TUI
TUI Adidas
Adidas Seidensticker
Seidensticker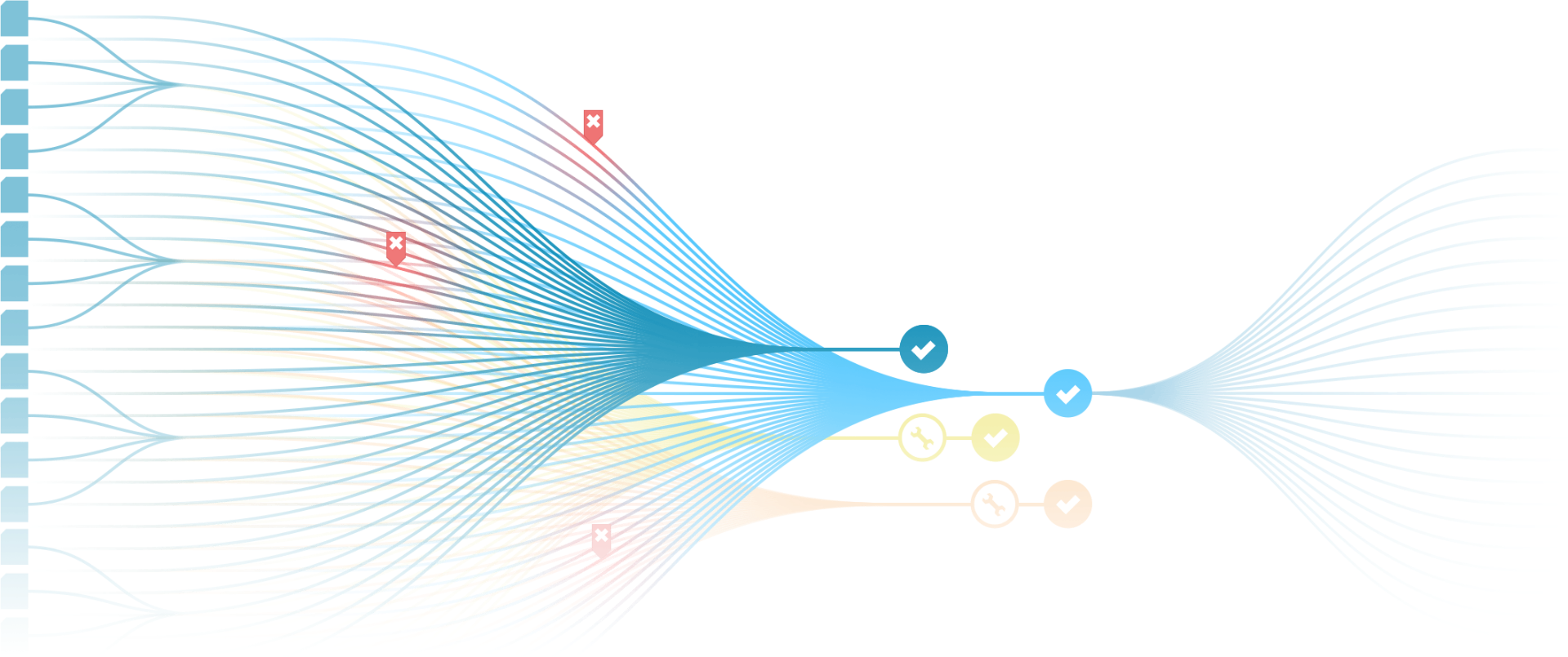
Deine Herausforderungen:Was DataNaicer für dich löst
Egal ob aus PDFs, Excel, XML oder Lieferantenkatalogen –
wir transformieren deine Rohdaten in perfekte Stammdaten.
Datenextraktion
Automatische Erkennung und Extraktion von Produktattributen aus Fließtexten, PDFs und unstrukturierten Quellen.
Datenbereinigung
Normalisierung und Harmonisierung von Einheiten, Auflösung von Synonymen und Korrektur von Tippfehlern.
Datenanreicherung
Fehlende Attribute automatisch ergänzen durch KI-Analyse und Integration externer Datenquellen.
Klassifizierung
Automatische Zuordnung zu deinem Datenstandard (z.B. ETIM, UNSPSC) und deinen eigenen Kategoriesystemen.
Lieferanten-Onboarding
Neue Lieferantendaten in jedem Format annehmen und automatisch in deine Struktur überführen.
Mehrsprachigkeit
Produktdaten in 40+ Sprachen übersetzen mit branchenspezifischem Fachvokabular.
Und das ist erst der Anfang
Entdecke alle 10 Kernfunktionen des DataNaicer im Detail.
Warum führende Unternehmenuns vertrauen
Basierend auf echtem Kundenfeedback: Die entscheidenden Faktoren für eine erfolgreiche Datenqualitäts-Partnerschaft.
Flatrate statt Kostenfalle
Unser Lizenzmodell basiert nicht auf der Anzahl deiner Artikel. Wettbewerber verlangen oft pro SKU, was bei Millionen Artikeln jeden Mehrwert für dich zerstört.
Ob 100.000 oder 5 Millionen SKUs – Deine Kosten bleiben kalkulierbar und transparent.
Ergebnisse, die überzeugen
Im Proof of Concept erreichen wir regelmäßig 9 von 10 korrekten Zuordnungen. Diese Qualität ist Voraussetzung für erfolgreiche Automatisierung.
Getestet und bestätigt von Großhandelsunternehmen mit Millionen Artikeln.
Von 30 % auf 100 % Abdeckung
Manuelle Datenanreicherung schafft oft nur 20–30 % der Artikel. Mit DataNaicer erreichst du vollumfängliche Anreicherung – automatisiert.
Was manuell 10 Jahre dauerte, erledigen wir in Wochen.
Spezialisten für Taxonomie
Wir fokussieren uns ausschließlich auf Datenqualität, Taxonomie und Textverarbeitung. Dieser Fokus zeigt sich in differenziertem Feedback und tiefem Verständnis.
Kein Bauchladen, sondern echte Fachkompetenz.
Partner auf Augenhöhe
Schnelle Reaktionszeiten, klare Kommunikation und professionelle Zusammenarbeit. Bei Problemen lösen wir schnell – das ist unser Anspruch.
Protokolle nach jedem Gespräch sorgen für Klarheit auf beiden Seiten.
Referenzen, die zählen
Namhafte Unternehmen aus Handel und Industrie vertrauen auf unsere Lösung. Der Erfolg unserer Kunden ist der beste Beweis.
Zielgerichtete Projektentscheidungen mit messbaren Meilensteinen.
“Der wichtigste Grund war das Lizenzmodell.”
Während Wettbewerber SKU-basierte Lizenzen anbieten, die bei Millionen Artikeln unwirtschaftlich skalieren, bietet uNaice ein faires Flatrate-Modell – ohne böse Überraschungen.
VollautomatisierungDer Flaschenhals bei der Datenpflege heißt „Mensch“
Deine Kunden erwarten perfekte Daten in Echtzeit. Aber manuelle Qualitätsprüfung skaliert nicht. Wir lösen dieses Dilemma.
Der Schlüssel zur Datenpflege-Automatisierung:
Verifizierbare Qualität
Du vertraust KI nicht 100 %ig? – Wir auch nicht!
Deshalb haben wir eine Lösung: Unsere Validation Station.
Sorgenfrei in die Daten-Zukunft!
Echtzeit-Verarbeitung
Neue Lieferantendaten werden sofort transformiert und sind in Minuten statt Tagen verfügbar.
Unbegrenzte Skalierung
Ob 1.000 oder 100.000 Datensätze – die Verarbeitungskapazität wächst ohne zusätzliches Personal.
Garantierte Qualität
Die Validation Station stellt sicher, dass trotz Automatisierung kein fehlerhafter Datensatz durchrutscht.
Bereit, den Bottleneck zu beseitigen?
Erfahre, wie die Validation Station die Grundlage für deine vollautomatisierte Datenverarbeitung schafft.
KundenstimmeWas unsere Kunden sagen
"Als Großhandel führen wir über 5 Millionen Artikel, deren Attribute unmöglich manuell angereichert werden können. Mit uNaice erreichen wir eine vollumfängliche Anreicherung, die wir manuell niemals hätten erreichen können. Der POC zeigte hervorragende Ergebnisse – neun von zehn waren korrekt."
Warum sich unsere Kunden für uNaice entscheiden
Fachkompetenz
Tiefes Verständnis für Taxonomie, Ontologie und Datenextraktion aus Texten – das unterschied uns von Anfang an.
Faire Flatrate
Unser Lizenzmodell wächst nicht mit der SKU-Anzahl. Bei 5 Millionen Artikeln ein entscheidender Vorteil.
Schnelle Reaktion
Bugs werden professionell und schnell gelöst. Das bewies: Wir handeln auch im Störfall zuverlässig.
Überzeugt? Starte jetzt.
Alle Features im Überblick
Von Datenextraktion bis zur Qualitätssicherung – alles aus einer Hand
Datenextraktion
Semantische Erkennung und Attributzuordnung. Text wird in strukturierte Daten umgewandelt – vollautomatisch.
Datenbereinigung
Automatische Bereinigung und Harmonisierung. Standardisierung von Zahlen, Auflösung von Synonymen und Vereinheitlichung.
Datenanreicherung
KI-gestützte Fließtextanalyse und Integration externer Quellen für vollständige Produktprofile.
Daten Detection
Dynamische Veränderungen in Datenstrukturen werden erkannt. Neue Felder und geänderte Formate automatisch identifiziert.
Datenintegration
Nahtlose Systemintegration in PIM, ERP oder Shopsysteme. Bidirektionale Synchronisation mit allen deinen Systemen.
Daten Mehrsprachigkeit
Übersetzung in 40+ Sprachen mit branchenspezifischem Vokabular und SEO-optimierter Lokalisierung.
Daten Ontologien
Der Ontology Creator beschleunigt die Ontologieerstellung und sorgt für hohe Datenqualität bei großen Datensätzen.
Datenannahme & Clearing
Der DataNaicer nimmt alles an – egal in welchem Format oder Zustand. Excel, XML oder Katalog – strukturiert oder unstrukturiert.
Datenmapping
KI-basierte Mapping-Vorschläge mit 80 % Auto-Rate. Intuitive Drag & Drop Oberfläche für schnelles Onboarding neuer Lieferanten.
Datenstandards/Klassifizierung
Native Integration von ECLASS, ETIM und UNSPSC. Automatische Klassifizierung und Zuordnung nach internationalen Standards.
Häufige Fragen zur automatisierten Datenveredelung
Bereit für automatisierteDatenqualität?
Probier es aus 100 Datensätze kostenlos und erlebe, wie der DataNaicer deine Datenqualität transformiert.