Datenaufbereitung für Unternehmen: Das Potenzial von Daten
Im folgenden Artikel nehmen wir dich an die Hand und führen dich durch die Welt der strukturierten Daten und der Datenaufbereitung. Was sind strukturierte Daten und wie unterscheiden sie sich von ihren unstrukturierten Namensbrüdern?
Lass uns gemeinsam entdecken, wie du in deinem Unternehmen strukturierte Daten effektiv nutzen kannst, um deine Geschäftsprozesse zu verbessern und die Rentabilität zu steigern.
Wie Datenaufbereitung die Herausforderung unstrukturierter Daten meistert
Wenn die Grundlage stimmt
Das A und O für eine gelungene automatisierte Textgenerierung durch den Textroboter bleiben gut strukturierte Daten, also die richtige Datengrundlage. Ein Teil davon besteht aus Stammdaten, die meist aus dem Produktmarketing erhältlich sind. In diesem Bereich tummeln sich unglaublich viele Informationen über das Produkt, die nur darauf warten, auch für die Content Automation genutzt zu werden.
Doch bei Weitem nicht alle Stammdaten eignen sich für eine maschinelle Auswertung, da sie oft in unterschiedlichen Formaten vorhanden und unvollständig sind oder redundante Informationen enthalten.
Das Datenfeld muss, um strukturiert zu sein, bestimmte Eigenschaften aufzeigen, die erst durch eine gezielte Datenaufbereitung gegeben sind. Nur dann nämlich kann der Textroboter schöne Texte automatisch erstellen. Schön heißt in diesem Kontext: informativ, unique, SEO-optimiert, mit Mehrwert und grammatikalisch korrekt.
Eine manuelle Bereinigung und Formatierung dieser Daten ist zeitaufwendig und fehleranfällig. Die Datenaufbereitung erfordert daher meist systematische Prozesse, die sicherstellen, dass die Daten korrekt und konsistent verarbeitet werden können.
Genau hier setzt der DataNaicer an. Das Tool von uNaice automatisiert viele der grundlegenden Schritte der Datenaufbereitung und bietet benutzerfreundliche Anpassungsoptionen für individuelle Anforderungen.
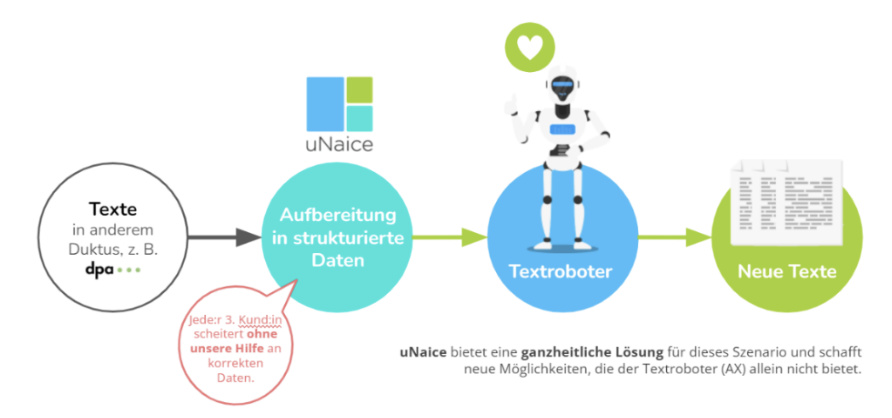
Datenaufbereitung im Fokus: Optimierte Produktdaten für nahtlose Content Automation
Oft verfügen Shopinhaber über Stammdaten wie Produktbeschreibungen, die in einem einzigen Datenfeld bereits die wichtigsten Merkmale enthalten. So praktisch das für einen Header sein mag, so nutzlos ist das für einen Textroboter. Da die Daten außerdem meist aus unterschiedlichen Quellen stammen, entsteht dadurch häufig noch mehr Datenchaos.
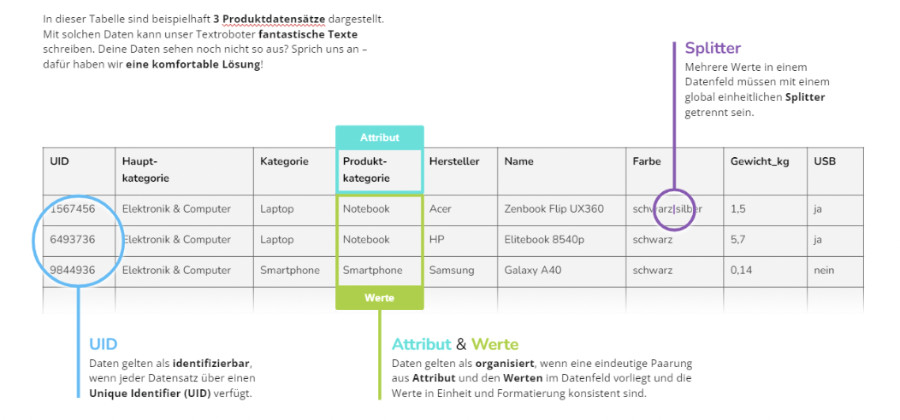
Reichhaltige Datenfelder beinhalten eine ganze Menge an verschwendeten Informationen, weil die darin enthaltenen Attribute nicht differenziert ausgelesen werden können. Wenn andererseits für jedes Attribut ein eigenes Datenfeld besteht ([Material], [Maße], [Farbe]), kann für jedes einzelne Attribut ein eigener Satz kreiert werden. Eine gründliche Datenaufbereitung trägt dazu bei, eine üppige Varianz zu schaffen, die Duplicate Content von vornherein ausschließt.
Fazit:
Je feingranularer und strukturierter die Daten sind (je mehr Datenfelder mit sauberer Befüllung ich habe), desto facettenreicher, detaillierter und flexibler wird die automatische Betextung ausfallen.
Häufigkeit und Befüllungsgrad
Granularität ist zwar wichtig, allerdings bringt es nichts, Datenfelder anzulegen, die sich nur auf wenige Produkte beziehen. Hier muss abgewogen werden, welche Attribute sich auf möglichst viele Produkte im Sortiment beziehen.
Attribut
= Merkmal oder Datenfeld (z.B. Farbe)
Befüllung
= Werte (z.B. rot, blau, weiß, grün …)
Qualität statt Quantität: Datenaufbereitung clever nutzen
In manchen Fällen kann es durchaus sinnvoll sein, nur gering befüllte Attribute für den Automated Content zu verwenden, nämlich dann, wenn genau diese Attribute eine Besonderheit darstellen.
Beispiel:
Die Applikation aus schillernden Perlen macht dieses T-Shirt zu einem wahren Hingucker.
Einzelne Datenfelder können sich auf mehrere Produkte beziehen. Somit wird Skalierbarkeit super einfach gemacht. Das Datenfeld „Betriebssystem" für einen Desktop-Computer kann etwa die Befüllung „Windows 10" enthalten – das ist absolut ok für einen Textroboter.
Funktionsweise des Textroboters: Die Rolle der Datenaufbereitung
Eigentlich ist der Textroboter wie eine Content-Abteilung. Wie diese benötigt er Produktdaten als Informationsquelle, um aussagekräftige Texte zu generieren. Doch dazu müssen Daten zu strukturierten Daten aufbereitet werden.

Was sind unstrukturierte Daten?
- Bei einem roten Kleid ist die Farbe „blau" hinterlegt
- Leere Felder
- Einige Autos haben „5" Sitze, der Rest hingegen „fünf"
Fazit: Mit Unregelmäßigkeiten jeglicher Art oder leeren Feldern kann ein Textroboter nicht gut arbeiten. Sie erschweren auch sonst jeglichen Workflow.
Was sind strukturierte Daten?
Strukturierte Daten sind Informationen, die in einem einheitlichen Format vorliegen, um z.B. Suchmaschinen bei der Interpretation und der Anzeige von Suchergebnissen zu unterstützen. Alle Informationen sind in einheitlichen Datenfeldern vorgegeben, wodurch sie leicht abrufbar werden.
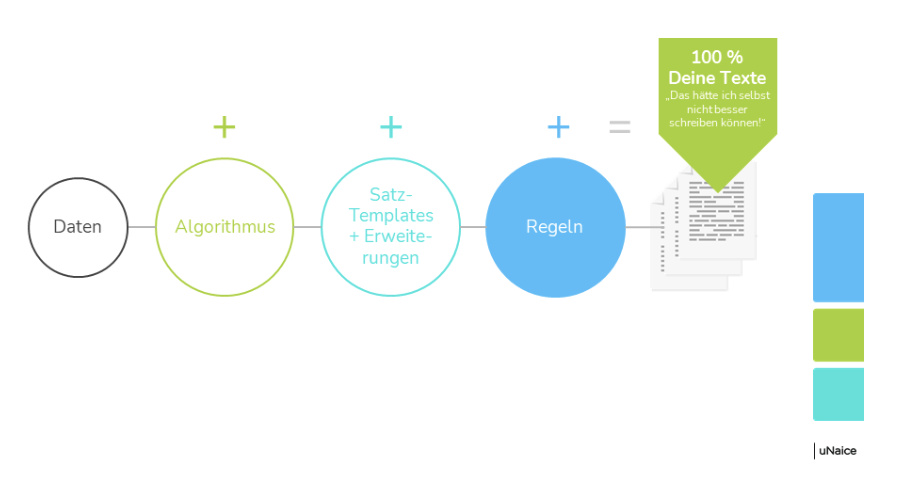
Der Algorithmus des Textroboters
Der Algorithmus bestimmt den syntaktischen und grammatikalischen Rahmen der Texte. Anders als eine KI trifft der Textroboter keine eigenmächtigen Entscheidungen und schreibt auch keine unbefugten Interpretationen.
Satz-Templates und Satzerweiterungen
Satztemplates und Satzerweiterungen ergeben Mustertexte, die mit etlichen Synonymen, Phrasen und Ergänzungen erweitert werden, die für sehr viel Varianz mit vielen informativen Inhalten sorgen.
Regelwerke
Durch den Einsatz von präzisen Regelwerken klingen Texte so, als ob du sie eigenhändig geschrieben hättest. Vorab wird genau definiert, welche Regeln nötig sind, damit die Texte genau deinen Bedürfnissen in Bezug auf Sprachauswahl, Sprachfärbung, Duktus und Tonalität entsprechen.
Daten wie ein Lückentext
Sind die Daten durch eine saubere Datenaufbereitung korrekt gepflegt, werden sie auch später im Text richtig ausgespielt. Praktisch kannst du sie dir wie einen Lückentext vorstellen, wobei der Textroboter die richtigen Attribute in die dafür vorgesehenen Lücken einfügt.
Es ist keine strukturierte Datengrundlage vorhanden?
Mit diesem Problem stehst du nicht alleine da. Aber keine Sorge! Eine fehlende Datenstruktur ist keine unüberwindbare Hürde.
Während der Zusammenarbeit mit unseren Kund:innen nehmen wir uns der Daten an und prüfen sie im Hinblick auf Struktur und Vollständigkeit. Eine ungenügende Datengrundlage kann durch unseren Eingriff wieder auf Vordermann gebracht werden.
Nice to know:
Strukturierte Daten bieten neben der Textautomation viele weitere Möglichkeiten. Na, neugierig geworden? Dann buche einen Termin und lass dir von unseren Experten alle Optionen aufzeigen.
Mehr erfahrenAus Daten werden Fließtexte: Was ein Textroboter so alles kann
Mit dem Textroboter eröffnen sich vielerlei Gestaltungsmöglichkeiten, die sich nicht nur auf Lückentexte reduzieren.
Beispiel: Opel Corsa – Der folgende Text ist der Anfang eines Blogbeitrags zum Opel Corsa F, einem charmanten Stadtflitzer.

Eine Gegenüberstellung der Daten und dem finalen Text ergibt, dass einige Stellen nicht übereinstimmen. Dabei handelt es sich um keine Fehler, sondern um bewusste Anpassungen im Rahmen der Datenaufbereitung, damit der Inhalt natürlich in den Text einfließt.
Interpretationen und Anpassungen
Meta-Daten und Datenaufbereitung
Sogenannte Meta-Daten, wie Verkaufszahlen, Retourendaten, Bewertungen anderer Käufer:innen, Shopinfos oder Herstellerdaten, sind für große E-Shops von besonders großem Interesse, da sie dem Textroboter eine interpretative Auslegung von Informationen ermöglichen.
Eine niedrige Retourenrate lässt etwa den Schluss zu, dass Kund:innen mit dem Produkt extrem zufrieden sind. Ein Satz wie folgender kann ausgespielt werden: „Ein besonders beliebtes Produkt, das Ihnen garantiert lange Freude bereitet."
Auch das kann der Textroboter
Damit du erkennst, welche Türen dir die Strukturierung deiner Daten eröffnet, geben wir dir hier einen kleinen Einblick:
Artikelvergleich
Produktvergleiche im Fließtext, sodass Produkte in Echtzeit miteinander verglichen werden können.
„Die Canon PowerShot SX500 IS gewinnt den Vergleich souverän."
Preisentwicklung
Wie verändern sich Autopreise im Verhältnis zur Lebensdauer und der gelaufenen Kilometerzahl?
Zulassungsstatistiken
Externe Quellen wie Zulassungsstatistiken bieten formidable Vergleichsmöglichkeiten für die Betextung.
Branchenübergreifend
Fahrräder, Dienstleistungen, Immobilien und vieles mehr – die Möglichkeiten sind endlos.
Schlusswort
Durch ein intelligentes Datenmanagement, eine clevere Datenaufbereitung und den Einsatz strukturierter Daten können Unternehmen Daten zu ihrem Vorteil nutzen. Über kurz oder lang wird das garantiert zu einem entscheidenden Wettbewerbsvorteil führen.