We extract, normalise and structure data from texts, tables and databases in a machine-readable format

Intelligent data preparation is the basis for the future of AI automation
Your new data structure enables search queries in natural language, automatic text generation, product recommendations and modern filter & comparison options for customers. You are also ideally positioned for AI-based applications.

The data software
Optimised (PIM-) master data for every application – also available in different languages at the touch of a button

Tables are no longer the way to go
Two-dimensional data structures are inflexible and can represent only a fraction of the information depth that modern web applications require. Mostly filled manually, they are also prone to inconsistencies, content errors and impure data records.
Automatic extraction without manual data processing
In order to cleanse your current data, we use algorithmic data analysis with machine learning techniques to extract it from any source, such as tables and texts. The analysis also detects impure information pairs, e.g. a color description hidden in a table field for general info. The entire process is automated, i.e. automated data processing.
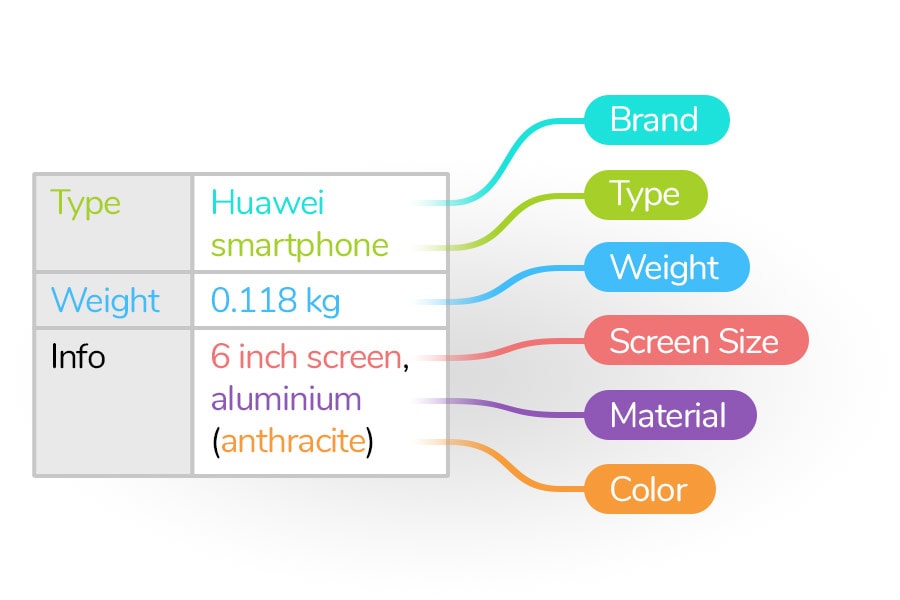
The DNA of Data: Attributes & Values
A new data collection is formed from the extracted data from all sources. It normalises itself and adds new data automatically. In this type of data preparation, logical links are formed that grow into a comprehensive and potentially complete data structure that contains only clean and machine-readable attribute-value pairings.
Ontology as a new structure
Instead of using inflexible tables, we organise your new data structure as an ontology – a method in the field of artificial intelligence. The intelligent system is rule-based and draws on a huge amount of experience from data sorting with similar topics, but can also be flexibly adapted to every need with individual rules.
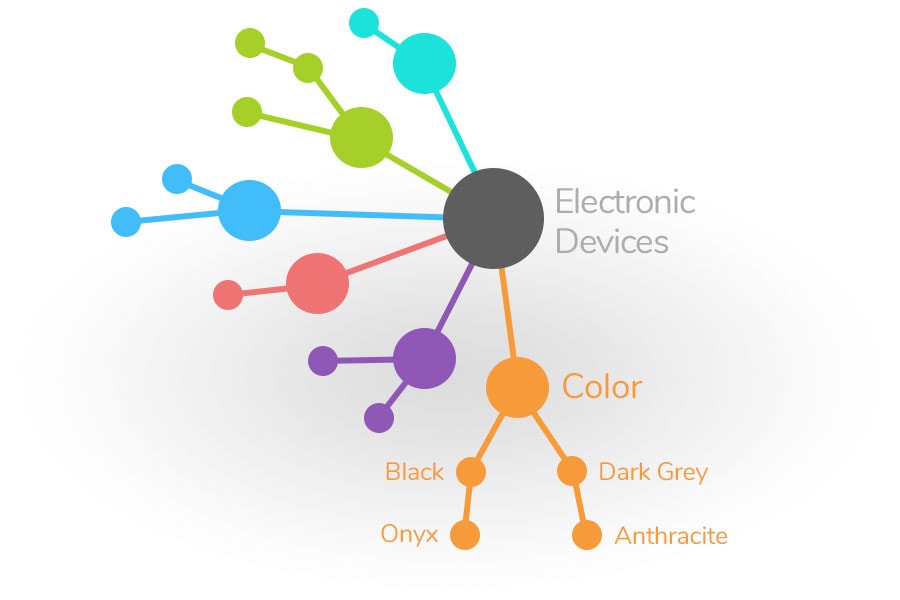
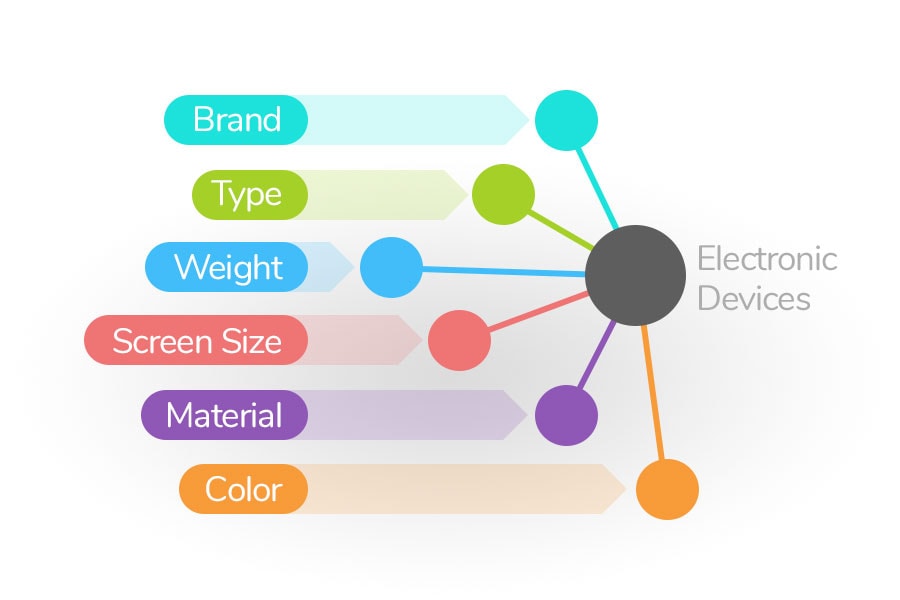
Why our structure is superior
Unlike text and tables that can represent a maximum of two-dimensional logic connections, the ontology as an intelligent system is capable of mapping a multidimensional data structure. This creates a higher-quality and cleaner information density.
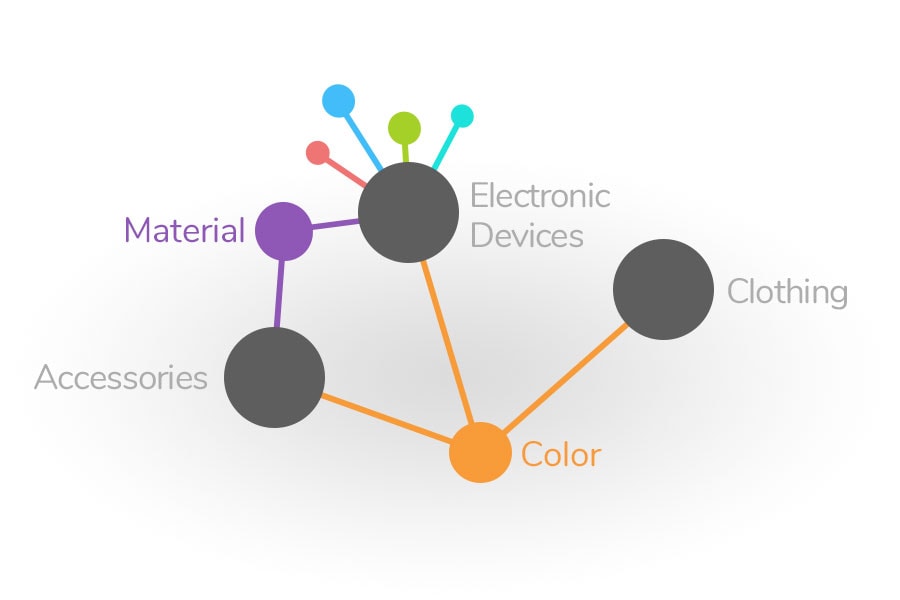
A real-world example: Attributes that are shared between multiple product groups (such as colour or material) only need to be maintained once and are then globally available.
Our packages
Find your perfect data match!
Starter
- ✔ 3 Data providers
- ✔ Up to 5.000 SKUs
- ✔ Excel, CSV
- ✔ Standard Data model
- ✔ No setup necessary
- ✔ Access to the Knowledge Base
Premium
- ✔ Up to 5 Data Providers
- ✔ Chat support & 3 30-minute web meetings per month
- ✔ Up to 20.000 SKUs in total
- ✔ Excel, CSV
- ✔ Standard Data model
- ✔ No setup necessary
- ✔ Access to the Knowledge Base
Enterprise
- ✔ Up to 10 data providers
- ✔ Chat support & 5 30-minute web meetings per month
- ✔ Personal Key Account Manager
- ✔ Unlimited SKUs
- ✔ Excel, CSV, XML, API
- ✔ Personalised data model
- ✔ One-time Setup
- ✔Strategy consulting
- ✔ Access to the knowledge base
Cancellable on a monthly basis
FAQs
Frequently asked questions – answers to the most important concerns
How do we ensure that new data sources are reliably integrated?
Each rule and each logic only needs to be created once – after that it is a permanent institution and works completely automatically. New data sources (e.g. from upstream suppliers) are reliably converted into the desired form. In addition, logical attributes can be added automatically. If something completely new comes along that cannot be displayed by the logic, a new rule is simply added to cover this circumstance. You will never have to manually enter a data record again.
Why is clean data so important?
Impure data is information that exists but is not uniform or comparable. This includes different units, terms in other languages or spelling mistakes. These seemingly marginal imperfections stand in your way when using modern applications such as product recommendations, comparisons and searches. The bounce rate of customers who can’t find what they’re looking for increases. We fix this inconsistent and impure data through intelligent data processing and create a clean, normalised data structure.
How does the technology contribute to improving data quality?
Our technology learns about your data and stores these findings in your ontology. For example, synonyms and names from other languages are used to enrich and improve your data. Frequent misspellings can be valuable information for applications, such as a product search. In addition, each data point is provided with meta-information to enrich your processes. For example, this can be weighting for sorting or inheriting attributes.
How much of your effort does it take?
We know that your time is precious. That is why we have developed an efficient process. No additional effort required – you can concentrate on your core business.