%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23a5d028;%20}%20.st1%20{%20fill:%20%23fff;%20}%20.st2%20{%20fill:%20%231de2db;%20}%20.st3%20{%20fill:%20%2341bdf9;%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='logo-unaice-line'%3e%3cpath%20class='st1'%20d='M143.3,36.1c-1.2,0-2.1-.9-2.1-2.1V12.2c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,1.2-.9,2.1-2.1,2.1ZM143.2,6.2c-1.3,0-2.4-1-2.4-2.4v-.8c0-1.3,1-2.4,2.4-2.4s2.4,1.1,2.4,2.4v.8c0,1.3-1.1,2.4-2.4,2.4Z'/%3e%3cpath%20class='st3'%20d='M23.7,36.1H2c-.5,0-1-.4-1-1V2.3c0-.5.4-1,1-1h21.7c.5,0,1,.4,1,1v32.9c0,.5-.4,1-1,1'/%3e%3cpath%20class='st2'%20d='M41.8,36.1h-14.4c-.5,0-1-.4-1-1v-14.5c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.5c0,.5-.4,1-1,1'/%3e%3cpath%20class='st0'%20d='M41.8,17.9h-14.4c-.5,0-1-.4-1-1V2.2c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.7c0,.5-.4,1-1,1'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M196.4,29.2c-2.1,2.1-3.6,3.2-7.1,3.2s-7.4-2.3-8.2-7.4h16.7c2.7,0,2.9-1.9,2.7-4-.7-6.2-5.3-11.2-11.6-11.2s-12.3,5.1-12.3,13.4,5.4,13.3,12.6,13.3,8.3-2.6,10-4.3c1.8-2.1-1.2-4.7-2.8-3ZM188.9,13.7c4.7,0,7.3,4.1,7.6,7.3h-15.3c.7-4.3,3.4-7.3,7.7-7.3Z'/%3e%3cpath%20class='st1'%20d='M132.1,12.9c-1.9-1.9-5.4-2.9-8.2-2.9s-5.3.5-8.2,1.8c-2.4,1-.9,5,1.6,3.7,2.1-1,3.3-1.5,6.3-1.5s6.7,1.1,6.8,6.1c-1.8-.5-2.7-.8-6.9-.8-6.8,0-11.3,3.3-11.3,8.8s4.1,8.4,10.1,8.4,5.4-.6,8.3-2.9v.5c0,2.8,4.2,2.6,4.2,0v-13.8c0-3.1-.8-5.5-2.7-7.4ZM130.4,26.2c0,3.6-3.4,6.3-8,6.3s-5.9-1.7-5.9-4.6,2.5-4.6,6.8-4.6c0,0,4.8,0,7.1,1v1.9Z'/%3e%3cpath%20class='st1'%20d='M80,36.1c-1.2,0-2.1-.9-2.1-2.1V3.4c0-1.2,1-2.2,2.2-2.2h.4c.8,0,1.4.4,2,1.1l20.2,25.7V3.4c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v30.7c0,1.1-.5,2-1.9,2s-1.9-.8-2.2-1.2l-20.7-26.2v25.3c0,1.2-.9,2.1-2.1,2.1Z'/%3e%3cpath%20class='st1'%20d='M60.2,36.5c-5.1,0-10.5-4.3-10.5-10.7v-13.5c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v13.1c0,4.5,2.5,7.1,6.6,7.1s7.3-3.2,7.3-7.5v-12.7c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,2.8-4.2,2.7-4.2,0v-.5c-1.5,1.6-3.3,2.9-7.6,2.9Z'/%3e%3cpath%20class='st1'%20d='M163.8,36.5c-7.1,0-13.1-6-13.1-13.3s4.8-13.5,13.5-13.5c4.4,0,6.9,2,8.8,3.7,1.8,1.5-.8,5.1-2.8,3.3-.8-.8-3.3-3-6.4-3-4.8,0-8.6,4-8.6,9.2s3.8,9.3,8.6,9.4c3.7,0,4.9-1,7-3.1,1.6-1.8,4.6,1,3,2.8-3,3-5.7,4.5-10,4.5h0Z'/%3e%3c/svg%3e)
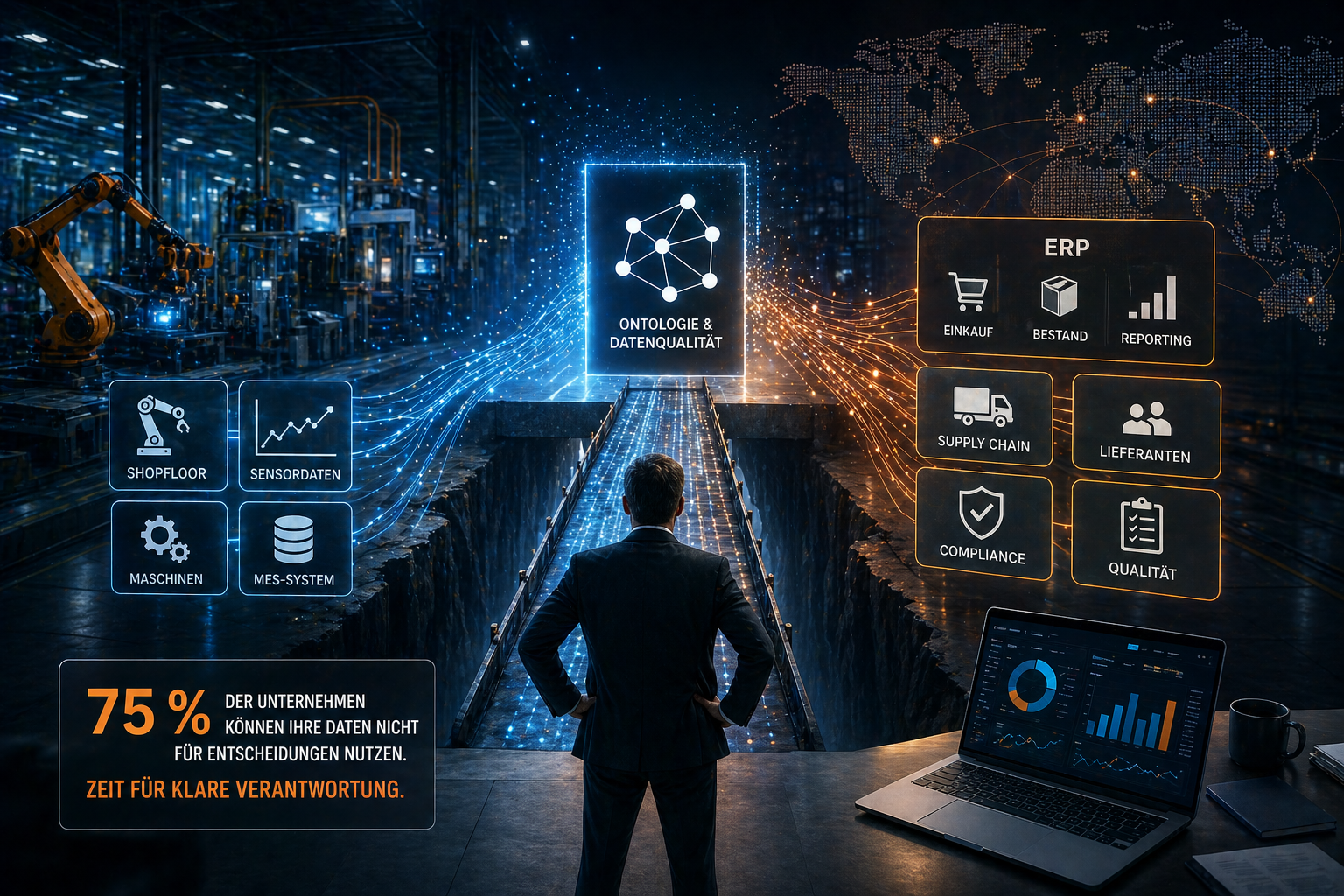
Die Zahlen überraschen: Laut einer aktuellen Studie von Dun & Bradstreet (2025) können nur 25 Prozent der deutschen Industrieunternehmen ihre vorhandenen Informationen für fundierte Geschäftsentscheidungen nutzen. Das bedeutet im Umkehrschluss, dass drei Viertel der Betriebe bei der Steuerung ihrer Lieferketten und Produktionsprozesse im Blindflug agieren. Fehlende Datenqualität gefährdet zunehmend die Wettbewerbsfähigkeit und Resilienz ganzer Produktionsstandorte.
Wenn das Fundament bröckelt, rückt schnell die Zuständigkeit in den Fokus. Oft stellt sich in diesem Chaos die zentrale Frage: Wer trägt im industriellen Umfeld die strategische Verantwortung für die Qualität der Prozessdaten? Ist es die IT-Abteilung, das Supply Chain Management oder direkt die Geschäftsführung?
In diesem Expertenratgeber klären wir diese Verantwortlichkeiten detailliert auf. Wir zeigen dir, warum klassische Excel-Schlachten ausgedient haben und wie du den „Flaschenhals Mensch" durch intelligente Ontologien und automatisierte Workflows dauerhaft überwindest.
uNaice verbindet Shopfloor und ERP-System über Datenschnittstellen, um isolierte Datensilos aufzulösen
Die Auflösung von Datensilos ermöglicht einen nahtlosen Informationsfluss zwischen Produktionsmaschinen (Shopfloor) und der zentralen Unternehmenssteuerung (ERP). Aktuell haben laut der Dun & Bradstreet-Erhebung (2025) nur 10 Prozent der befragten Unternehmen zentrale Prozesse wie Lieferantenbewertungen oder Risikoanalysen vollständig automatisiert. Der Rest kämpft mit manuellen Übertragungen und isolierten Systemen, die nicht miteinander kommunizieren.
Um diese Lücke zu schließen, reicht es nicht aus, einfache Tabellen von A nach B zu kopieren. Die Lösung liegt im Aufbau eines semantischen Datenmodells. Anstatt Daten in starren Relationen einzusperren, organisieren moderne Systeme Informationen als Ontologie. Diese Methode der Künstlichen Intelligenz (KI) versteht die logischen Zusammenhänge zwischen einem Maschinensensor, dem produzierten Bauteil und dem dazugehörigen Lieferantenvertrag.
Wenn du diese Brücke schlägst, wird dein Datenkapital effizient nutzbar. Systembrüche verschwinden, und die automatisierte Aufbereitung von Produktdaten sowie Maschinendaten erfolgt in Echtzeit, was manuelle Fehlerquoten drastisch reduziert.
Welche Schnittstellenkonzepte eignen sich am besten für die Echtzeit-Integration von externen Lieferantendaten?
Moderne Schnittstellenkonzepte bestehen aus drei Hauptkomponenten:
Die Transparenz in Lieferketten ist ein kritischer Schwachpunkt. Die Studie von Dun & Bradstreet zeigt, dass lediglich 13 Prozent der deutschen Unternehmen über eine vollständige Sicht bis in die tieferen Zulieferstrukturen verfügen.
Besonders die Integration unstrukturierter externer Logistikdaten stellt eine massive Hürde dar. Lieferanten senden Spezifikationen oft als unübersichtliche PDF-Dokumente, in verschachtelten Excel-Listen oder über veraltete EDI-Standards. Ein starres Schnittstellenkonzept scheitert hier an der Heterogenität der Formate.
Wir haben in unserer Praxis gesehen, dass die semantische Datenextraktion hier den entscheidenden Unterschied macht. KI-gestützte Systeme lesen diese Dokumente aus, normalisieren unterschiedliche Maßeinheiten automatisch und reichern fehlende Attribute durch externe Quellen an. So entsteht aus einem fehlerhaften Lieferantenkatalog ein perfekter Stammdatensatz, der sofort im ERP-System verarbeitet werden kann.
Warum scheitern viele Industrieunternehmen an der nahtlosen Verknüpfung von MES- und Supply-Chain-Daten?
Im Gegensatz zu homogenen IT-Landschaften bietet die industrielle Realität eine historisch gewachsene Mischung aus inkompatiblen Systemen und proprietären Protokollen. Die Verknüpfung von Manufacturing Execution Systems (MES) mit Supply-Chain-Daten scheitert in der Praxis meist an der fehlenden Datenreife. Eine Transformationsstudie von NTT DATA und Natuvion (2025) belegt dies deutlich: Für über 56 Prozent der befragten Führungskräfte ist schlechte Datenqualität das Transformations-Hindernis Nummer eins.
Das Problem liegt oft in der Semantik. Das MES auf dem Shopfloor benennt ein Bauteil nach technischen Spezifikationen, während das Supply-Chain-System denselben Artikel unter einer kaufmännischen Lieferantennummer führt. Ohne ein intelligentes Mapping entstehen Dubletten, Fehlbestände und Produktionsverzögerungen.
Zudem versuchen viele Unternehmen, dieses Problem durch manuelle Datenpflege zu lösen. Dieser Ansatz ist bei Millionen von Artikeln nicht skalierbar. Der Frust über unsaubere Lieferantendaten und der immense Zeitverlust bei der Produktpflege bremsen die Agilität des gesamten Unternehmens massiv aus.
Die Kernfrage: Wer trägt im industriellen Umfeld die strategische Verantwortung für die Qualität der Prozessdaten?
Das Management von Prozessdaten umfasst die Sicherstellung von Datenqualität, Compliance und Nutzbarkeit entlang der Wertschöpfungskette. Laut Fraunhofer (2025) müssen Daten nach den gleichen Prinzipien bewirtschaftet werden wie andere strategische Unternehmensressourcen. Die Verantwortung lässt sich daher nicht auf eine einzelne IT-Abteilung abwälzen, sondern erfordert ein Zusammenspiel verschiedener Akteure.
Die Rolle der Geschäftsführung (C-Level)
Das C-Level definiert die übergeordnete Datenstrategie und stellt die notwendigen Budgets für Infrastruktur und Automatisierung bereit. Die Geschäftsführung trägt die Letztverantwortung für regulatorische Compliance. Da Vorschriften zu Nachhaltigkeit (ESG) und Lieferkettensorgfalt zunehmen, müssen Geschäftsführer sicherstellen, dass Transparenz datenbasiert abgesichert ist. Wer trägt im industriellen Umfeld die strategische Verantwortung für die Qualität der Prozessdaten, wenn es um Haftungsfragen geht? Eindeutig die Unternehmensleitung, die das Thema Datenqualität zur Chefsache machen muss.
Die Aufgabe der Supply Chain und Produktionsleiter
Supply Chain Manager nutzen Prozessdaten, um Engpässe frühzeitig zu erkennen und die Resilienz der Lieferkette zu erhöhen. Da aktuell 85 Prozent der Hersteller Nearshoring-Strategien verfolgen (Dun & Bradstreet, 2025), benötigen diese Fachabteilungen fehlerfreie Stammdaten, um neue Lieferanten schnell anzubinden. Sie sind die Data Owner und definieren, welche fachlichen Anforderungen an die Datenqualität gestellt werden. Die IT fungiert lediglich als Enabler, der die Werkzeuge für diese Fachbereiche bereitstellt.
Möchtest du wissen, wie du diese Verantwortlichkeiten in deinem Unternehmen durch klare Prozesse und smarte Tools unterstützen kannst? uNaice bietet Beratungsdienstleistungen zur Entwicklung und Implementierung einer strukturierten Datenstrategie.
Wie löst KI-gestütztes Datenmanagement den manuellen Flaschenhals in der Produktion?
KI-gestützte Datenaufbereitung ermöglicht die vollautomatisierte Transformation unstrukturierter Rohdaten in fehlerfreie Stammdaten und spart bis zu 75 Prozent der manuellen Arbeitszeit ein. Wenn Unternehmen wachsen und die Artikelanzahl von 10.000 auf 5 Millionen Datensätze steigt, kollabieren manuelle Prozesse unweigerlich. Genau hier setzen wir bei uNaice an.
Unser Tool löst die Handbremse im Datenmanagement. Anstatt Mitarbeiter mit repetitiven Excel-Korrekturen zu binden, übernimmt die KI das Auslesen, Bereinigen und Strukturieren. Der entscheidende Unterschied zu einer reinen „Blackbox-KI" ist unsere Qualitätsgarantie: Das System kombiniert 99 Prozent KI-Automatisierung mit einer intelligenten Validation Station. Hier prüfen menschliche Experten gezielt nur noch die komplexesten Ausnahmefälle, was eine 100-prozentige Fehlerfreiheit der Stammdaten garantiert.
Skalierung durch planbare Flatrate-Modelle
Ein Flatrate-Preismodell ermöglicht die Verarbeitung von Millionen Datensätzen ohne unkalkulierbare Kosten pro SKU. In der Industrie ist Kostensicherheit ein entscheidender Faktor. Deshalb berechnen wir keine Gebühren pro Artikel oder Textvariante. Deine Softwarelösung wächst mit deinem Unternehmen, ohne, dass du neues Personal für die Datenpflege einstellen musst.
Diese Kombination aus technologischer Exzellenz „Made in Germany", DSGVO-Konformität und garantierter Datenqualität ist der Grund, warum Marktführer wie adidas, TUI oder Otto auf unsere Expertise bei der Stammdaten-Perfektion vertrauen.
Fazit: Datenqualität ist das Fundament der Industrie 4.0
Die Frage: Wer trägt im industriellen Umfeld die strategische Verantwortung für die Qualität der Prozessdaten?, lässt sich abschließend klar beantworten: Es ist eine gemeinsame Aufgabe von Management, Fachbereichen und IT. Doch Verantwortung allein reicht nicht aus, wenn die Werkzeuge fehlen. Solange hochqualifizierte Mitarbeiter ihre Zeit mit dem manuellen Korrigieren von Tippfehlern in Lieferantendaten verschwenden, bleibt die digitale Transformation in den Kinderschuhen stecken.
Datenqualität ist längst keine Option mehr, sondern die Grundvoraussetzung für wettbewerbsfähige Entscheidungen, funktionierende Lieferketten und rechtliche Compliance. Wer seine Daten als echtes Kapital begreift und in automatisierte Qualitäts-Pipelines investiert, sichert sich einen massiven Wettbewerbsvorteil in einem zunehmend volatilen Markt.
Befreie dein Team von manueller Datenpflege und mach deine Stammdaten fit für die Zukunft. Vereinbare jetzt ein kostenloses Erstgespräch oder schau dir die Leistungsfähigkeit unserer KI direkt an deinen eigenen Daten an – nutze unseren unverbindlichen 100 Datensätze Test und erlebe perfekte Datenqualität auf Knopfdruck.
Häufig gestellte Fragen (FAQ)
Bereit für den nächsten Schritt?
Kontaktiere uns für eine unverbindliche Beratung zu deinem Datenprojekt.
Jetzt Kontakt aufnehmenQuellen
