%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23a5d028;%20}%20.st1%20{%20fill:%20%23fff;%20}%20.st2%20{%20fill:%20%231de2db;%20}%20.st3%20{%20fill:%20%2341bdf9;%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='logo-unaice-line'%3e%3cpath%20class='st1'%20d='M143.3,36.1c-1.2,0-2.1-.9-2.1-2.1V12.2c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,1.2-.9,2.1-2.1,2.1ZM143.2,6.2c-1.3,0-2.4-1-2.4-2.4v-.8c0-1.3,1-2.4,2.4-2.4s2.4,1.1,2.4,2.4v.8c0,1.3-1.1,2.4-2.4,2.4Z'/%3e%3cpath%20class='st3'%20d='M23.7,36.1H2c-.5,0-1-.4-1-1V2.3c0-.5.4-1,1-1h21.7c.5,0,1,.4,1,1v32.9c0,.5-.4,1-1,1'/%3e%3cpath%20class='st2'%20d='M41.8,36.1h-14.4c-.5,0-1-.4-1-1v-14.5c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.5c0,.5-.4,1-1,1'/%3e%3cpath%20class='st0'%20d='M41.8,17.9h-14.4c-.5,0-1-.4-1-1V2.2c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.7c0,.5-.4,1-1,1'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M196.4,29.2c-2.1,2.1-3.6,3.2-7.1,3.2s-7.4-2.3-8.2-7.4h16.7c2.7,0,2.9-1.9,2.7-4-.7-6.2-5.3-11.2-11.6-11.2s-12.3,5.1-12.3,13.4,5.4,13.3,12.6,13.3,8.3-2.6,10-4.3c1.8-2.1-1.2-4.7-2.8-3ZM188.9,13.7c4.7,0,7.3,4.1,7.6,7.3h-15.3c.7-4.3,3.4-7.3,7.7-7.3Z'/%3e%3cpath%20class='st1'%20d='M132.1,12.9c-1.9-1.9-5.4-2.9-8.2-2.9s-5.3.5-8.2,1.8c-2.4,1-.9,5,1.6,3.7,2.1-1,3.3-1.5,6.3-1.5s6.7,1.1,6.8,6.1c-1.8-.5-2.7-.8-6.9-.8-6.8,0-11.3,3.3-11.3,8.8s4.1,8.4,10.1,8.4,5.4-.6,8.3-2.9v.5c0,2.8,4.2,2.6,4.2,0v-13.8c0-3.1-.8-5.5-2.7-7.4ZM130.4,26.2c0,3.6-3.4,6.3-8,6.3s-5.9-1.7-5.9-4.6,2.5-4.6,6.8-4.6c0,0,4.8,0,7.1,1v1.9Z'/%3e%3cpath%20class='st1'%20d='M80,36.1c-1.2,0-2.1-.9-2.1-2.1V3.4c0-1.2,1-2.2,2.2-2.2h.4c.8,0,1.4.4,2,1.1l20.2,25.7V3.4c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v30.7c0,1.1-.5,2-1.9,2s-1.9-.8-2.2-1.2l-20.7-26.2v25.3c0,1.2-.9,2.1-2.1,2.1Z'/%3e%3cpath%20class='st1'%20d='M60.2,36.5c-5.1,0-10.5-4.3-10.5-10.7v-13.5c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v13.1c0,4.5,2.5,7.1,6.6,7.1s7.3-3.2,7.3-7.5v-12.7c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,2.8-4.2,2.7-4.2,0v-.5c-1.5,1.6-3.3,2.9-7.6,2.9Z'/%3e%3cpath%20class='st1'%20d='M163.8,36.5c-7.1,0-13.1-6-13.1-13.3s4.8-13.5,13.5-13.5c4.4,0,6.9,2,8.8,3.7,1.8,1.5-.8,5.1-2.8,3.3-.8-.8-3.3-3-6.4-3-4.8,0-8.6,4-8.6,9.2s3.8,9.3,8.6,9.4c3.7,0,4.9-1,7-3.1,1.6-1.8,4.6,1,3,2.8-3,3-5.7,4.5-10,4.5h0Z'/%3e%3c/svg%3e)
Wenn Maschinen und ERP aneinander vorbeireden
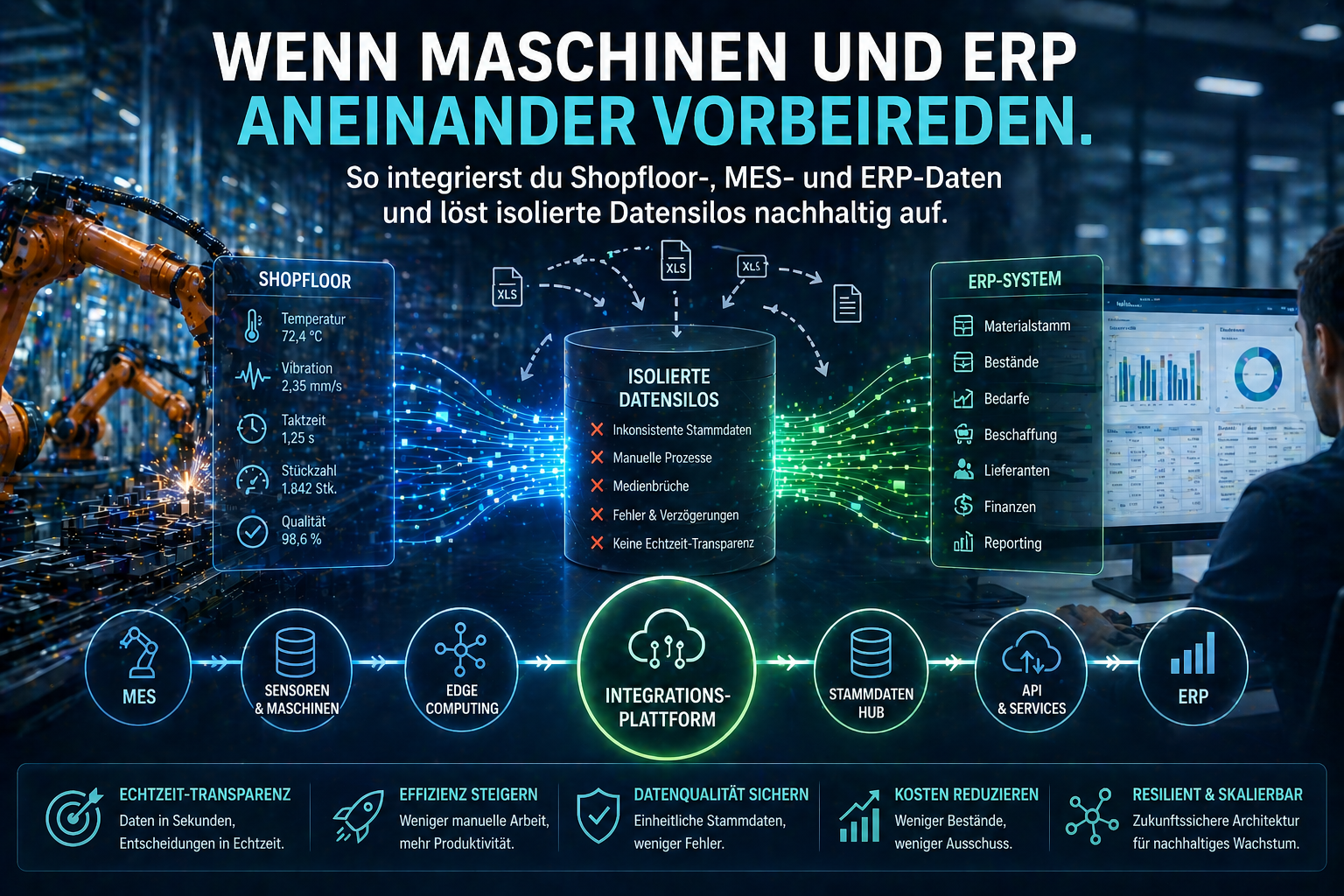
Die Produktionslinie läuft, das MES erfasst Tausende Datenpunkte pro Minute – und trotzdem tippt jemand im Büro Zahlen manuell in eine Excel-Tabelle, weil das ERP-System die Shopfloor-Daten schlicht nicht kennt. Dieses Szenario erleben wir bei uNaice in fast jedem Erstgespräch mit Produktionsleitern und Supply Chain Managern.
Der eigentliche Engpass ist dabei selten die Technik. Es sind isolierte Datensilos, die über Jahre gewachsen sind. Die Datenintegration zwischen Shopfloor und ERP-System umfasst drei Ebenen: Architektur, Organisation und Datenqualität. In diesem Artikel zeigen wir dir Schritt für Schritt, wie du diese Silos aufbrichst – mit konkreten Methoden, die in der Praxis funktionieren.
Warum scheitern viele Industrieunternehmen an der Verknüpfung von MES- und ERP-Daten?
Die häufigste Ursache für gescheiterte Integrationen ist nicht fehlende Software, sondern inkonsistente Stammdaten. Wenn Materialnummern im MES anders heißen als im ERP, wenn Einheiten nicht normalisiert sind und wenn Lieferantendaten in drei verschiedenen Excel-Formaten vorliegen, scheitert jede Schnittstelle – egal wie modern sie ist.
Wir sehen bei unseren Kunden regelmäßig drei Kernprobleme:
Der „Flaschenhals Mensch“ zeigt sich hier besonders deutlich: Teams verbringen Stunden damit, Daten zwischen Systemen abzugleichen, statt Produktionsprozesse zu optimieren.
Welche Schnittstellenkonzepte eignen sich für die Echtzeit-Integration von Shopfloor- und ERP-Daten?
Echtzeit-Schnittstellenkonzepte für die Shopfloor-ERP-Integration lassen sich in drei Kategorien einteilen: Punkt-zu-Punkt-Verbindungen, Middleware-basierte Architekturen und Event-Driven-Ansätze. Jede Kategorie hat spezifische Stärken je nach Datenvolumen und Latenzanforderung.
Punkt-zu-Punkt vs. Middleware vs. Event-Driven
Für Produktionsumgebungen mit hohem Datenaufkommen empfehlen wir bei uNaice eine Kombination: Edge-Computing direkt am Shopfloor für zeitkritische Sensordaten und eine Middleware-Schicht für die strukturierte Übergabe an das ERP-System.
Wann Edge-Computing der Cloud-Lösung vorzuziehen ist
Edge-Computing ist der Cloud-Lösung immer dann vorzuziehen, wenn Latenzzeiten unter 100 Millisekunden gefordert sind oder sensible Produktionsdaten das Werksgelände nicht verlassen dürfen. Typische Anwendungsfälle sind Echtzeit-Qualitätsprüfungen und Maschinensteuerung. Die Cloud eignet sich dagegen für historische Analysen, Predictive Maintenance und die Aggregation standortübergreifender Daten.
Schritt-für-Schritt: Isolierte Datensilos zwischen Shopfloor und ERP-System auflösen
Die nachhaltige Auflösung von Datensilos erfordert einen strukturierten Prozess in fünf Phasen. Wir haben diesen Ansatz in zahlreichen Projekten erprobt – unter anderem mit Unternehmen wie adidas und Otto, die auf uNaice vertrauen.
Phase 1: Dateninventur und Qualitätsanalyse
Eine Dateninventur ist die systematische Erfassung aller vorhandenen Datenquellen, Formate und Qualitätsniveaus. Starte mit einer Bestandsaufnahme: Welche Systeme erzeugen welche Daten? Wo gibt es Redundanzen? Wo fehlen Attribute? Unsere Erfahrung zeigt, dass Unternehmen im Schnitt 30 bis 40 Prozent ihrer Stammdaten als fehlerhaft oder unvollständig einstufen, wenn sie erstmals systematisch hinschauen.
Phase 2: Datenmodell und Ontologie aufbauen
Eine Ontologie ist ein semantisches Datenmodell, das Beziehungen zwischen Objekten maschinenlesbar abbildet – im Gegensatz zu starren Tabellen, die nur Zeilen und Spalten kennen. Bei uNaice nutzen wir Ontologien als Wissensgraphen, um Produktdaten logisch zu verstehen. Das ist der Unterschied zur „Blackbox-KI“: Statt Textbausteine zu würfeln, erkennt das System, dass „M8x30 Edelstahl A2“ und „Schraube DIN 912 8×30 V2A“ das selbe Bauteil beschreiben.
Dieser Schritt ist entscheidend, damit professionelles Datenmanagement in der Industrie überhaupt funktionieren kann.
Phase 3: Automatisierte Stammdatenbereinigung
Automatisierte Stammdatenbereinigung umfasst die Normalisierung von Einheiten, Korrektur von Tippfehlern und Anreicherung fehlender Attribute durch externe Quellen. Manuelle Excel-Schlachten sind hier der größte Zeitfresser. Wir haben erlebt, dass Teams wochenlang Lieferantenkataloge abgleichen – bei Tausenden von SKUs eine Sisyphusarbeit.
Mit dem DataNaicer automatisierst du diesen Prozess: 99 Prozent KI-Automatisierung, kombiniert mit der Validation Station für 100 Prozent Fehlerfreiheit. Und das Beste: uNaice berechnet keine Kosten pro SKU. Ob 10.000 oder 5 Millionen Datensätze – die Flatrate macht den ROI planbar.
Phase 4: Schnittstellen implementieren und testen
Die Schnittstellenimplementierung verbindet die bereinigten Stammdaten mit MES, ERP und weiteren Zielsystemen über standardisierte APIs. Achte auf bidirektionale Datenflüsse: Der Shopfloor liefert Ist-Daten ans ERP, das ERP gibt Soll-Vorgaben zurück. Teste jeden Datenfluss mit realen Produktionsdaten, bevor du live gehst.
Phase 5: Data Governance etablieren
Data Governance bezeichnet die organisatorische Verantwortung für Datenqualität, Zugriffsrechte und Änderungsprozesse. Ohne klare Governance wachsen neue Silos innerhalb von Monaten nach. Die Definition eines Data Owners pro Datendomäne setzt Kenntnisse der Produktion und der IT-Landschaft voraus. Die strategische Verantwortung für Prozessdatenqualität sollte auf Abteilungsleiter-Ebene liegen.
Wie historische Maschinendaten Predictive Maintenance und OEE-Berechnung ermöglichen
Historische Maschinendaten sind die Grundlage für Predictive Maintenance, weil sie Verschleißmuster sichtbar machen, die in Echtzeit-Daten allein nicht erkennbar sind. Voraussetzung ist eine lückenlose Erfassung über mindestens sechs bis zwölf Monate.
Für die Echtzeit-Berechnung der Overall Equipment Effectiveness benötigst du drei Datenstrukturen: Verfügbarkeitsdaten (geplante vs. ungeplante Stillstände), Leistungsdaten (Soll- vs. Ist-Taktzeit) und Qualitätsdaten (Gutteile vs. Ausschuss). Wenn diese Daten aus unterschiedlichen Silos stammen, ist eine korrekte OEE-Berechnung unmöglich.
Drohende Produktionsengpässe lassen sich durch die intelligente Auswertung von Sensordaten frühzeitig identifizieren – vorausgesetzt, Temperatur-, Vibrations- und Druckwerte fließen in ein zentrales Monitoring ein, statt in isolierten Steuerungen zu verschwinden.
Rückverfolgbarkeit und Datenschutz beim externen Datenaustausch sicherstellen
Lückenlose Rückverfolgbarkeit (Traceability) erfordert eine durchgängige Verknüpfung von Chargen-, Lieferanten- und Fertigungsdaten über alle Wertschöpfungsstufen hinweg. Gerade beim Datenaustausch mit externen Zulieferern ist der Schutz sensibler Produktionsdaten entscheidend.
Bewährte Schutzmaßnahmen umfassen:
Bei uNaice legen wir besonderen Wert auf Standortsicherheit und DSGVO-Konformität – „Made in Germany“, betrieben von einem leidenschaftlichen Expertenteam. Unstrukturierte externe Logistikdaten integrierst du am besten über standardisierte Formate wie EDIFACT oder API-basierte Konnektoren in dein Supply-Chain-Monitoring.
Möchtest du sehen, wie sich isolierte Datensilos zwischen Shopfloor und ERP-System nachhaltig auflösen lassen – konkret an deinen eigenen Daten? Teste die Qualität mit dem kostenlosen 100-Datensätze-Test.
Fazit: Datensilos aufzulösen ist kein IT-Projekt, sondern eine strategische Entscheidung
Die Auflösung von Datensilos zwischen Shopfloor und ERP gelingt nur, wenn Datenqualität, Schnittstellenarchitektur und organisatorische Governance zusammenspielen. Technik allein reicht nicht – du brauchst saubere Stammdaten als Fundament, eine skalierbare Integrationsschicht und klare Verantwortlichkeiten.
uNaice transformiert unstrukturierte Rohdaten in strukturierte Stammdaten. Von 10.000 bis 5 Millionen Datensätzen – ohne zusätzliches Personal, ohne Kosten pro SKU. Buche jetzt eine kostenlose Online-Demo und sieh live, wie die Qualitäts-Pipeline deine Datensilos auflöst.
Häufig gestellte Fragen
Bereit für den nächsten Schritt?
Kontaktiere uns für eine unverbindliche Beratung zu deinem Datenprojekt.
Jetzt Kontakt aufnehmenQuellen
