%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23a5d028;%20}%20.st1%20{%20fill:%20%23fff;%20}%20.st2%20{%20fill:%20%231de2db;%20}%20.st3%20{%20fill:%20%2341bdf9;%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='logo-unaice-line'%3e%3cpath%20class='st1'%20d='M143.3,36.1c-1.2,0-2.1-.9-2.1-2.1V12.2c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,1.2-.9,2.1-2.1,2.1ZM143.2,6.2c-1.3,0-2.4-1-2.4-2.4v-.8c0-1.3,1-2.4,2.4-2.4s2.4,1.1,2.4,2.4v.8c0,1.3-1.1,2.4-2.4,2.4Z'/%3e%3cpath%20class='st3'%20d='M23.7,36.1H2c-.5,0-1-.4-1-1V2.3c0-.5.4-1,1-1h21.7c.5,0,1,.4,1,1v32.9c0,.5-.4,1-1,1'/%3e%3cpath%20class='st2'%20d='M41.8,36.1h-14.4c-.5,0-1-.4-1-1v-14.5c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.5c0,.5-.4,1-1,1'/%3e%3cpath%20class='st0'%20d='M41.8,17.9h-14.4c-.5,0-1-.4-1-1V2.2c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.7c0,.5-.4,1-1,1'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M196.4,29.2c-2.1,2.1-3.6,3.2-7.1,3.2s-7.4-2.3-8.2-7.4h16.7c2.7,0,2.9-1.9,2.7-4-.7-6.2-5.3-11.2-11.6-11.2s-12.3,5.1-12.3,13.4,5.4,13.3,12.6,13.3,8.3-2.6,10-4.3c1.8-2.1-1.2-4.7-2.8-3ZM188.9,13.7c4.7,0,7.3,4.1,7.6,7.3h-15.3c.7-4.3,3.4-7.3,7.7-7.3Z'/%3e%3cpath%20class='st1'%20d='M132.1,12.9c-1.9-1.9-5.4-2.9-8.2-2.9s-5.3.5-8.2,1.8c-2.4,1-.9,5,1.6,3.7,2.1-1,3.3-1.5,6.3-1.5s6.7,1.1,6.8,6.1c-1.8-.5-2.7-.8-6.9-.8-6.8,0-11.3,3.3-11.3,8.8s4.1,8.4,10.1,8.4,5.4-.6,8.3-2.9v.5c0,2.8,4.2,2.6,4.2,0v-13.8c0-3.1-.8-5.5-2.7-7.4ZM130.4,26.2c0,3.6-3.4,6.3-8,6.3s-5.9-1.7-5.9-4.6,2.5-4.6,6.8-4.6c0,0,4.8,0,7.1,1v1.9Z'/%3e%3cpath%20class='st1'%20d='M80,36.1c-1.2,0-2.1-.9-2.1-2.1V3.4c0-1.2,1-2.2,2.2-2.2h.4c.8,0,1.4.4,2,1.1l20.2,25.7V3.4c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v30.7c0,1.1-.5,2-1.9,2s-1.9-.8-2.2-1.2l-20.7-26.2v25.3c0,1.2-.9,2.1-2.1,2.1Z'/%3e%3cpath%20class='st1'%20d='M60.2,36.5c-5.1,0-10.5-4.3-10.5-10.7v-13.5c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v13.1c0,4.5,2.5,7.1,6.6,7.1s7.3-3.2,7.3-7.5v-12.7c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,2.8-4.2,2.7-4.2,0v-.5c-1.5,1.6-3.3,2.9-7.6,2.9Z'/%3e%3cpath%20class='st1'%20d='M163.8,36.5c-7.1,0-13.1-6-13.1-13.3s4.8-13.5,13.5-13.5c4.4,0,6.9,2,8.8,3.7,1.8,1.5-.8,5.1-2.8,3.3-.8-.8-3.3-3-6.4-3-4.8,0-8.6,4-8.6,9.2s3.8,9.3,8.6,9.4c3.7,0,4.9-1,7-3.1,1.6-1.8,4.6,1,3,2.8-3,3-5.7,4.5-10,4.5h0Z'/%3e%3c/svg%3e)
When Machines and ERP Systems talk past each other
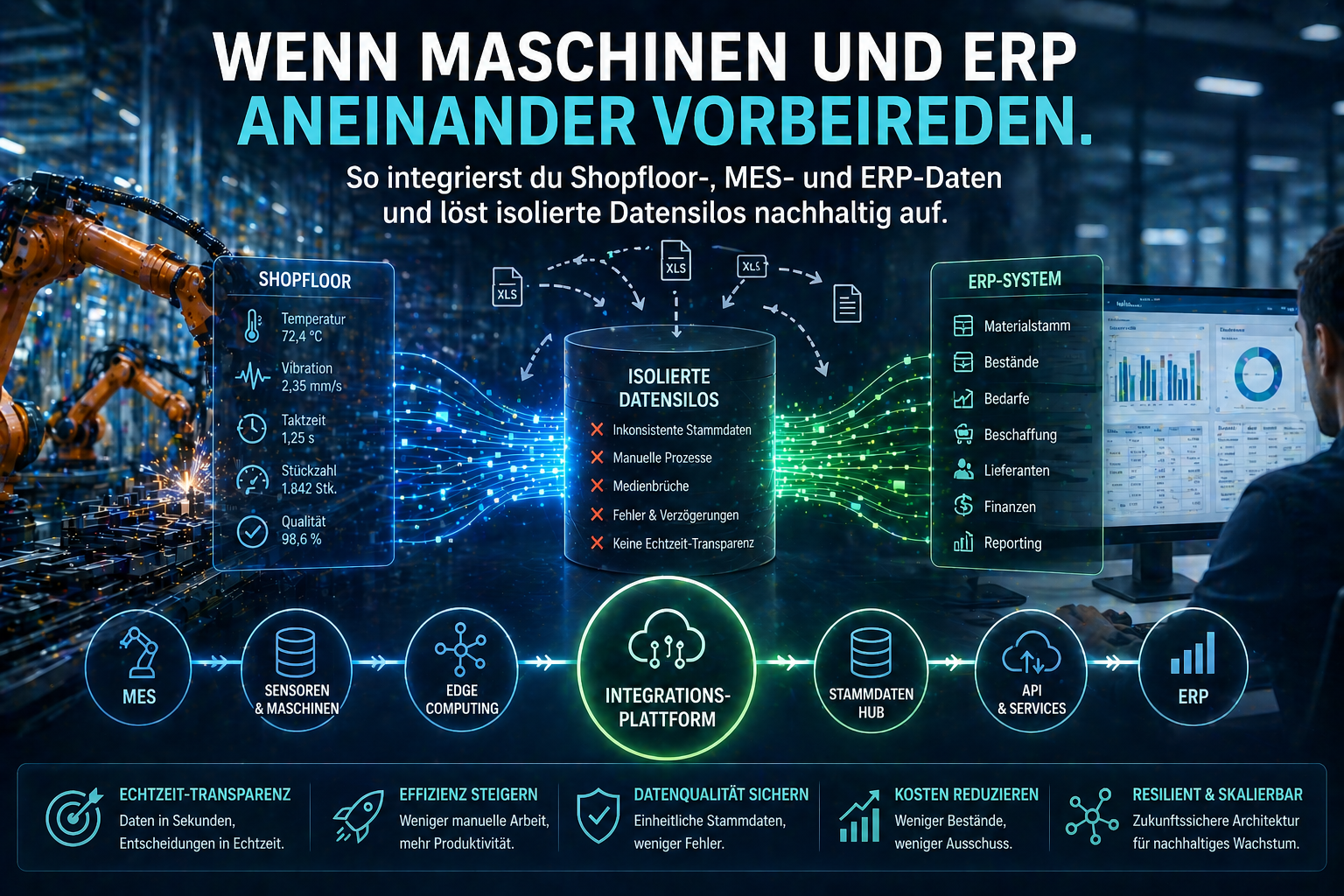
The production line is running, the MES captures thousands of data points per minute—and yet someone in the office is still manually entering numbers into an Excel spreadsheet because the ERP system simply doesn’t have access to the shop floor data. We encounter this scenario at uNaice in nearly every initial meeting with production managers and supply chain managers.
The real bottleneck here is rarely the technology. It’s isolated data silos that have grown over the years. Data integration between the shop floor and the ERP system involves three levels: architecture, organization, and data quality. In this article, we’ll show you step by step how to break down these silos—with concrete methods that work in practice.
Why do many industrial companies fail to link MES and ERP data?
The most common cause of failed integrations is not a lack of software, but inconsistent master data. If material numbers are labeled differently in the MES than in the ERP, if units are not standardized, and if supplier data is stored in three different Excel formats, every interface will fail—no matter how modern it is.
We regularly see three core issues among our clients:
The “human bottleneck” is particularly evident here: teams spend hours reconciling data between systems instead of optimizing production processes.
Which interface concepts are suitable for the real-time integration of shop floor and ERP data?
Real-time interface concepts for shop floor-ERP integration can be divided into three categories: point-to-point connections, Middleware-based architectures, and event-driven approaches. Each category has specific strengths depending on data volume and latency requirements.
Point-to-Point vs. Middleware vs. Event-Driven
For production environments with high data volumes, we at uNaice recommend a combination: Edge computing directly on the shop floor for time-critical sensor data and a Middleware layer for structured transfer to the ERP system.
When Edge Computing is preferable to a Cloud Solution
Edge computing is always preferable to a cloud solution when latency must be under 100 milliseconds or when sensitive production data must not leave the factory premises. Typical use cases include real-time quality inspections and machine control. The cloud, on the other hand, is suitable for historical analyses, predictive maintenance, and the aggregation of cross-site data.
Step-by-step: Breaking down isolated data silos between the shop floor and the ERP system
The sustainable elimination of data silos requires a structured five-phase process. We have tested this approach in numerous projects—including with companies such as adidas and Otto, who rely on uNaice.
Phase 1: Data Inventory and Quality Analysis
A data inventory is the systematic documentation of all existing data sources, formats, and quality levels. Start by taking stock: Which systems generate which data? Where are there redundancies? Where are attributes missing? Our experience shows that companies classify an average of 30 to 40 percent of their master data as erroneous or incomplete when they examine it systematically for the first time.
Phase 2: Building the Data Model and Ontology
An ontology is a semantic data model that maps relationships between objects in a machine-readable way—unlike rigid tables, which only recognize rows and columns. At uNaice, we use ontologies as knowledge graphs to logically understand product data. This is the difference from “black-box AI”: Instead of shuffling text blocks, the system recognizes that “M8x30 stainless steel A2” and “screw DIN 912 8×30 V2A” describe the same component.
This step is crucial for professional data management in industry to function at all.
Phase 3: Automated Master Data Cleansing
Automated master data cleansing involves normalizing units, correcting typos, and enriching missing attributes using external sources. Manual Excel battles are the biggest time-sink here. We’ve seen teams spend weeks reconciling supplier catalogs—a Sisyphean task when dealing with thousands of SKUs.
With DataNaicer, you can automate this process: 99% AI automation, combined with the Validation Station for 100% accuracy. And best of all: uNaice does not charge per SKU. Whether it’s 10,000 or 5 million records—the flat rate makes ROI predictable.
Phase 4: Implement and Test Interfaces
Interface implementation connects the cleaned master data with MES, ERP, and other target systems via standardized APIs. Ensure bidirectional data flows: The shop floor delivers actual data to the ERP, and the ERP returns target specifications. Test every data flow with real production data before going live.
Phase 5: Establish Data Governance
Data governance refers to the organizational responsibility for data quality, access rights, and change management processes. Without clear governance, new silos will form within months. Defining a Data Owner for each data domain requires knowledge of both production and the IT landscape. Strategic responsibility for process data quality should lie at the department head level.
How historical machine data enables predictive maintenance and OEE calculation
Historical machine data forms the basis for predictive maintenance because it reveals wear patterns that cannot be detected in real-time data alone. This requires complete data collection over a period of at least six to twelve months.
To calculate Overall Equipment Effectiveness in real time, you need three data sets: availability data (planned vs. unplanned downtime), performance data (target vs. actual cycle time), and quality data (good parts vs. scrap). If this data comes from different silos, an accurate OEE calculation is impossible.
Impending production bottlenecks can be identified early through the intelligent analysis of sensor data—provided that temperature, vibration, and pressure values are fed into a central monitoring system rather than disappearing into isolated control systems.
Ensuring traceability and data protection during external data exchange
Seamless traceability requires a consistent linkage of batch, supplier, and production data across all stages of the value chain. Protecting sensitive production data is particularly crucial when exchanging data with external suppliers.
Proven security measures include:
At uNaice, we place particular emphasis on location security and GDPR compliance – “Made in Germany,” operated by a passionate team of experts. The best way to integrate unstructured external logistics data into your supply chain monitoring is via standardized formats such as EDIFACT or API-based connectors.
Would you like to see how isolated data silos between the shop floor and the ERP system can be permanently eliminated—using your own data as a concrete example? Test the quality with the free 100-data-record trial.
Conclusion: Breaking down data silos is not an IT project, but a strategic decision
Breaking down data silos between the shop floor and ERP can only succeed when data quality, interface architecture, and organizational governance work together. Technology alone is not enough—you need clean master data as a foundation, a scalable integration layer, and clear responsibilities.
uNaice transforms unstructured raw data into structured master data. From 10,000 to 5 million records—without additional staff and without per-SKU costs. Book a free online demo now and see firsthand how the quality pipeline breaks down your data silos.
Frequently Asked Questions
Ready for the next step?
Contact us for a no-obligation consultation about your data project.
Contact us nowSources
