%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23a5d028;%20}%20.st1%20{%20fill:%20%23fff;%20}%20.st2%20{%20fill:%20%231de2db;%20}%20.st3%20{%20fill:%20%2341bdf9;%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='logo-unaice-line'%3e%3cpath%20class='st1'%20d='M143.3,36.1c-1.2,0-2.1-.9-2.1-2.1V12.2c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,1.2-.9,2.1-2.1,2.1ZM143.2,6.2c-1.3,0-2.4-1-2.4-2.4v-.8c0-1.3,1-2.4,2.4-2.4s2.4,1.1,2.4,2.4v.8c0,1.3-1.1,2.4-2.4,2.4Z'/%3e%3cpath%20class='st3'%20d='M23.7,36.1H2c-.5,0-1-.4-1-1V2.3c0-.5.4-1,1-1h21.7c.5,0,1,.4,1,1v32.9c0,.5-.4,1-1,1'/%3e%3cpath%20class='st2'%20d='M41.8,36.1h-14.4c-.5,0-1-.4-1-1v-14.5c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.5c0,.5-.4,1-1,1'/%3e%3cpath%20class='st0'%20d='M41.8,17.9h-14.4c-.5,0-1-.4-1-1V2.2c0-.5.4-1,1-1h14.4c.5,0,1,.4,1,1v14.7c0,.5-.4,1-1,1'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M196.4,29.2c-2.1,2.1-3.6,3.2-7.1,3.2s-7.4-2.3-8.2-7.4h16.7c2.7,0,2.9-1.9,2.7-4-.7-6.2-5.3-11.2-11.6-11.2s-12.3,5.1-12.3,13.4,5.4,13.3,12.6,13.3,8.3-2.6,10-4.3c1.8-2.1-1.2-4.7-2.8-3ZM188.9,13.7c4.7,0,7.3,4.1,7.6,7.3h-15.3c.7-4.3,3.4-7.3,7.7-7.3Z'/%3e%3cpath%20class='st1'%20d='M132.1,12.9c-1.9-1.9-5.4-2.9-8.2-2.9s-5.3.5-8.2,1.8c-2.4,1-.9,5,1.6,3.7,2.1-1,3.3-1.5,6.3-1.5s6.7,1.1,6.8,6.1c-1.8-.5-2.7-.8-6.9-.8-6.8,0-11.3,3.3-11.3,8.8s4.1,8.4,10.1,8.4,5.4-.6,8.3-2.9v.5c0,2.8,4.2,2.6,4.2,0v-13.8c0-3.1-.8-5.5-2.7-7.4ZM130.4,26.2c0,3.6-3.4,6.3-8,6.3s-5.9-1.7-5.9-4.6,2.5-4.6,6.8-4.6c0,0,4.8,0,7.1,1v1.9Z'/%3e%3cpath%20class='st1'%20d='M80,36.1c-1.2,0-2.1-.9-2.1-2.1V3.4c0-1.2,1-2.2,2.2-2.2h.4c.8,0,1.4.4,2,1.1l20.2,25.7V3.4c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v30.7c0,1.1-.5,2-1.9,2s-1.9-.8-2.2-1.2l-20.7-26.2v25.3c0,1.2-.9,2.1-2.1,2.1Z'/%3e%3cpath%20class='st1'%20d='M60.2,36.5c-5.1,0-10.5-4.3-10.5-10.7v-13.5c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v13.1c0,4.5,2.5,7.1,6.6,7.1s7.3-3.2,7.3-7.5v-12.7c0-1.2.9-2.1,2.1-2.1s2.1.9,2.1,2.1v21.8c0,2.8-4.2,2.7-4.2,0v-.5c-1.5,1.6-3.3,2.9-7.6,2.9Z'/%3e%3cpath%20class='st1'%20d='M163.8,36.5c-7.1,0-13.1-6-13.1-13.3s4.8-13.5,13.5-13.5c4.4,0,6.9,2,8.8,3.7,1.8,1.5-.8,5.1-2.8,3.3-.8-.8-3.3-3-6.4-3-4.8,0-8.6,4-8.6,9.2s3.8,9.3,8.6,9.4c3.7,0,4.9-1,7-3.1,1.6-1.8,4.6,1,3,2.8-3,3-5.7,4.5-10,4.5h0Z'/%3e%3c/svg%3e)
The figures are surprising: According to a recent study by Dun & Bradstreet (2025), only 25 percent of German industrial companies are able to use their existing information to make informed business decisions. Conversely, this means that three-quarters of companies are operating blindly when it comes to managing their supply chains and production processes. Poor data quality is increasingly jeopardizing the competitiveness and resilience of entire production sites.
When the foundation crumbles, the focus quickly shifts to accountability. Amid this chaos, the central question often arises: Who bears strategic responsibility for the quality of process data in an industrial setting? Is it the IT department, Supply Chain Management, or directly the executive management?
In this expert guide, we explain these responsibilities in detail. We'll show you why traditional Excel battles are a thing of the past and how you can permanently overcome the "human bottleneck" through intelligent ontologies and automated workflows.
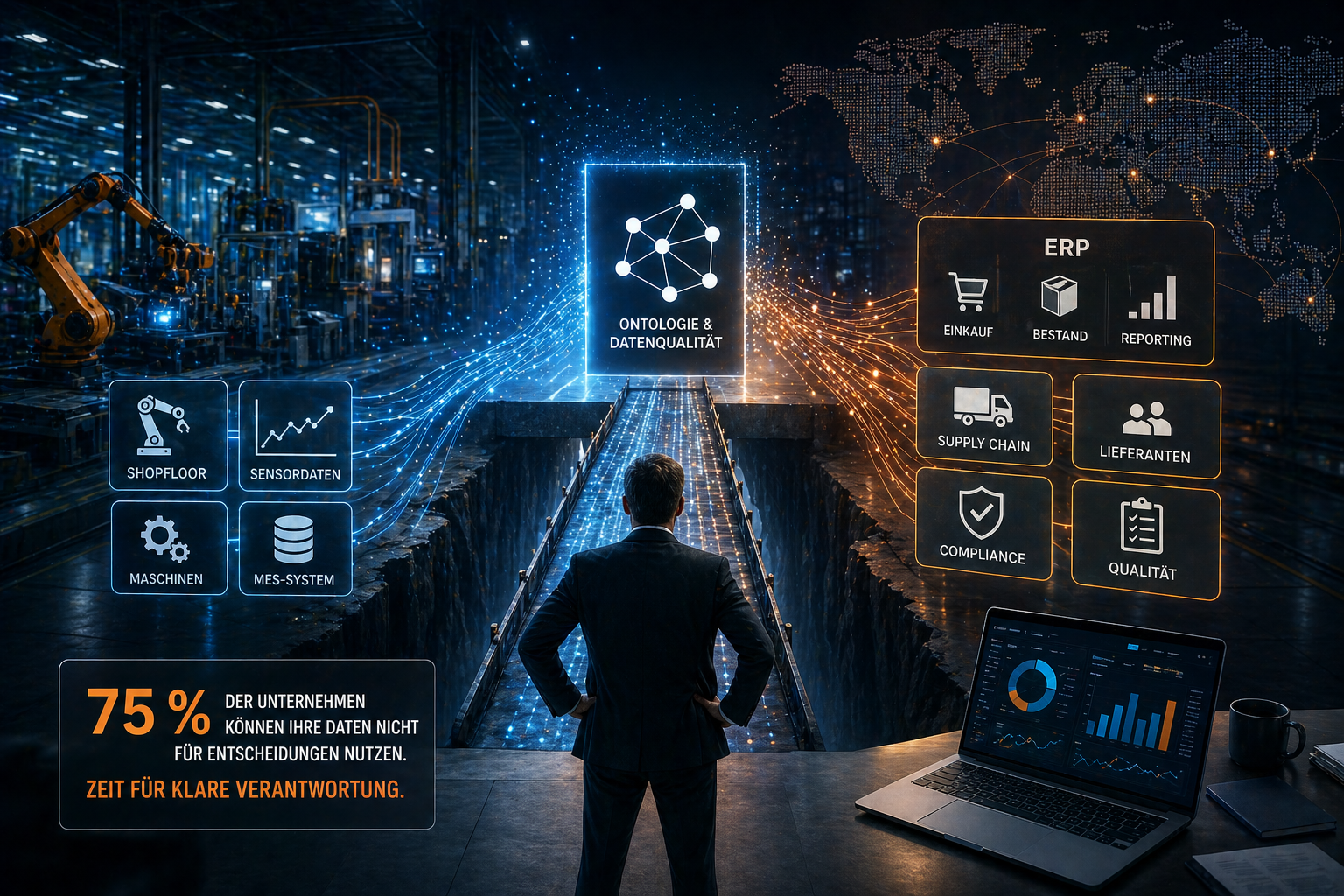
uNaice connects the shop floor and ERP system via data interfaces to break down isolated data silos
Breaking down data silos enables a seamless flow of information between production machines (shop floor) and central enterprise management (ERP). According to the Dun & Bradstreet survey (2025), only 10 percent of the companies surveyed have fully automated core processes such as supplier evaluations or risk analyses. The rest struggle with manual data transfers and isolated systems that do not communicate with one another.
To close this gap, simply copying tables from A to B is not enough. The solution lies in building a semantic data model. Instead of locking data into rigid relationships, modern systems organize information as an ontology. This artificial intelligence (AI) method understands the logical connections between a machine sensor, the manufactured component, and the corresponding supplier contract.
Once you bridge this gap, your data assets become efficiently usable. System silos disappear, and the automated processing of product data as well as machine data occurs in real time, drastically reducing manual error rates.
Which interface concepts are best suited for the real-time integration of external supplier data?
Modern interface concepts consist of three main components:
Transparency in supply chains is a critical weak point. The study by Dun & Bradstreet shows that only 13 percent of German companies have a complete view down into the deeper supplier structures.
In particular, integrating unstructured external logistics data poses a massive challenge. Suppliers often send specifications as cluttered PDF documents, in nested Excel spreadsheets, or via outdated EDI standards. A rigid interface approach fails here due to the heterogeneity of formats.
In our experience, we have seen that semantic data extraction makes the decisive difference here. AI-powered systems parse these documents, automatically normalize different units of measurement, and enrich missing attributes using external sources. This transforms an error-prone supplier catalog into a perfect master data record that can be processed immediately in the ERP system.
Why do many industrial companies struggle to seamlessly integrate MES and supply chain data?
Unlike homogeneous IT landscapes, the industrial reality offers a historically evolved mix of incompatible systems and proprietary protocols. In practice, the integration of Manufacturing Execution Systems (MES) with supply chain data usually fails due to a lack of data maturity. A transformation study by NTT DATA and Natuvion (2025) clearly demonstrates this: For over 56 percent of the executives surveyed, poor data quality is the number one obstacle to transformation.
The problem often lies in the terminology. The MES on the shop floor identifies a component by its technical specifications, while the supply chain system lists the same item under a commercial supplier number. Without intelligent mapping, this leads to duplicate entries, stock shortages, and production delays.
In addition, many companies attempt to solve this problem through manual data maintenance. This approach is not scalable when dealing with millions of items. Frustration over inaccurate supplier data and the immense amount of time lost to product maintenance severely hinder the agility of the entire company.
The key question: Who bears strategic responsibility for the quality of process data in an industrial setting?
Process data management involves ensuring data quality, compliance, and usability throughout the value chain. According to Fraunhofer (2025), data must be managed according to the same principles as other strategic corporate resources. Responsibility cannot therefore be shifted to a single IT department but requires collaboration among various stakeholders.
The Role of Executive Management (C-Level)
The C-level defines the overarching data strategy and allocates the necessary budgets for infrastructure and automation. Executive management bears ultimate responsibility for regulatory compliance. As regulations regarding sustainability (ESG) and supply chain due diligence increase, executives must ensure that transparency is data-driven. In an industrial setting, who bears strategic responsibility for the quality of process data when it comes to liability issues? Clearly, it is senior management, which must make data quality a top priority.
The Role of Supply Chain and Production Managers
Supply chain managers use process data to identify bottlenecks early and increase supply chain resilience. Since 85 percent of manufacturers are currently pursuing nearshoring strategies (Dun & Bradstreet, 2025), these departments need error-free master data to quickly onboard new suppliers. They are the Data Owners and define the technical requirements for data quality. IT acts merely as an enabler, providing the tools for these departments.
Would you like to know how you can support these responsibilities in your company through clear processes and smart tools? uNaice offers consulting services for the development and implementation of a structured data strategy.
How does AI-powered data management resolve manual bottlenecks in production?
AI-powered data processing enables the fully automated transformation of unstructured raw data into error-free master data and saves up to 75 percent of manual labor time. As companies grow and the number of items increases from 10,000 to 5 million records, manual processes inevitably collapse. This is exactly where we at uNaice come in.
Our tool removes the bottleneck in data management. Instead of tying up employees with repetitive Excel corrections, AI handles the extraction, cleaning, and structuring of data. The key difference from pure "black-box AI" is our quality guarantee: The system combines 99 percent AI automation with an intelligent Validation Station. Here, human experts specifically review only the most complex exceptions, ensuring 100 percent accuracy of master data.
Scalability through predictable flat-rate models
A flat-rate pricing model enables the processing of millions of data records without unpredictable costs per SKU. In industry, cost certainty is a decisive factor. That's why we don't charge fees per item or text variant. Your software solution grows with your business without requiring you to hire new staff for data maintenance.
This combination of technological excellence "Made in Germany," GDPR compliance, and guaranteed data quality is why market leaders such as adidas, TUI, and Otto rely on our expertise in master data perfection.
Conclusion: Data quality is the foundation of Industry 4.0
The question: Who bears strategic responsibility for the quality of process data in an industrial setting? can be clearly answered: It is a shared responsibility of management, business units, and IT. But responsibility alone is not enough if the tools are missing. As long as highly qualified employees waste their time manually correcting typos in supplier data, digital transformation will remain in its infancy.
Data quality is no longer an option, but rather a prerequisite for competitive decision-making, functioning supply chains, and legal compliance. Those who view their data as a true asset and invest in automated quality pipelines secure a massive competitive advantage in an increasingly volatile market.
Free your team from manual data maintenance and get your master data ready for the future. Schedule a free initial consultation now or see how our AI performs on your own data—try our no-obligation 100-record trial and experience perfect data quality at the click of a button.
Frequently Asked Questions (FAQ)
Ready for the next step?
Contact us for a no-obligation consultation about your data project.
Contact us nowSources
