Wir extrahieren, normalisieren und strukturieren Daten aus Texten, Tabellen und Datenbanken in maschinenlesbarer Form

Intelligente Datenaufbereitung ist die Grundlage für die Zukunft der KI-Automatisierung
Deine neue Datenstruktur ermöglicht Suchanfragen in natürlicher Sprache, automatische Texterstellung, Produktempfehlungen sowie moderne Filter- & Vergleichsmöglichkeiten für Kunden. Ganz nebenbei bist du für KI-basierte Anwendungen optimal aufgestellt.

Die Datensoftware
Optimierete (PIM-)Stammdaten für jeden Anwendungsfall – auf Knopfdruck auch in verschiedenen Sprachen

Tabellen sind nicht mehr zeitgemäß
Zweidimensionale Datenstrukturen sind unflexibel und können nur einen Bruchteil der Informationstiefe darstellen, die moderne Web-Anwendungen benötigen. Zumeist händisch befüllt sind sie zudem anfällig für Inkonsistenzen, inhaltliche Fehler und unreine Datensätze.
Automatische Extraktion ohne händische Datenaufbereitung
Durch algorithmische Datenanalyse mit Techniken aus dem maschinellen Lernen extrahieren wir zur Bereinigung deine relevanten Bestandsdaten aus beliebigen Quellen wie Tabellen und Texten. Durch die Analyse werden auch unreine Informationspaarungen erkannt, wie z. B. eine Farbbeschreibung, die sich in einem Tabellenfeld für allgemeine Infos versteckt. Der komplette Prozess ist automatisiert, sprich eine automatisierte Datenaufbereitung.

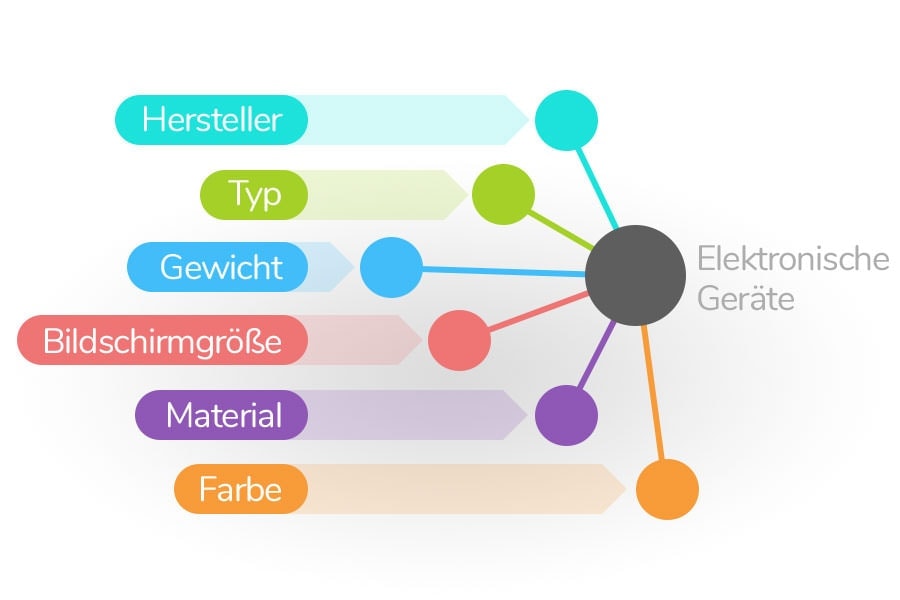
Die Daten-DNA: Attribute & Werte
Aus den extrahierten Daten aller Quellen wird eine neue Datensammlung gebildet. Diese ergänzt und normalisiert sich automatisch. In dieser Datenaufbereitung werden logische Verknüpfungen gebildet, die zu einer umfassenden und potenziell lückenlosen Datenstruktur heranwachsen, die nur saubere und maschinenlesbare Attribut-Werte-Paarungen enthält.
Die Ontologie als neue Struktur
Statt einer starren Tabelle organisieren wir deine neue Datenstruktur als Ontologie – eine Methode aus dem Bereich der künstlichen Intelligenz. Das intelligente System ist regelbasiert und greift auf einen riesigen Stamm an Erfahrungswerten aus bereits absolvierten, themennahen Datensortierungen zurück, kann aber auch mit individuellen Regeln an jedes Bedürfnis flexibel angepasst werden.
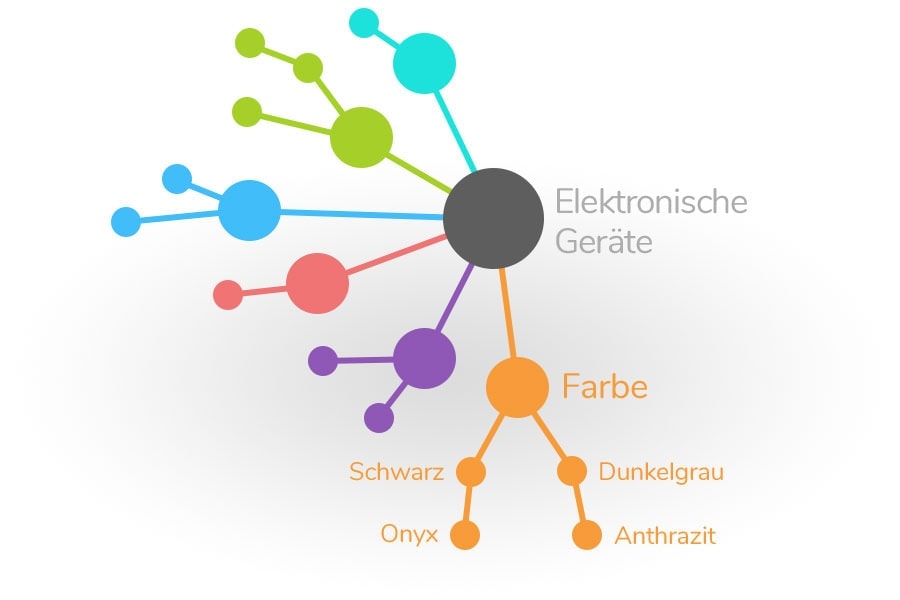

Warum unsere Struktur wirklich überlegen ist
Im Gegensatz zu Texten und Tabellen, die ein- oder maximal zweidimensionale Logikverbindungen abbilden können, ist die Ontologie als intelligentes System fähig, eine multidimensionale Datenstruktur abzubilden. Dies schafft generell eine hochwertigere und reinere Informationsdichte.
Ein Beispiel aus der Praxis: Attribute, die sich mehrere Produktgruppen teilen (z. B. Farbe oder Material), müssen nur einmal gepflegt werden und sind anschließend global verfügbar.
Unsere Pakete
Finde dein perfektes Daten-Match!
Starter
- ✔ 3 Datenlieferanten
- ✔ Bis zu 5.000 SKUs
- ✔ Excel, CSV
- ✔ Standard Datenmodell
- ✔ Kein Setup notwendig
- ✔ Zugang zur Knowlegdebase
Premium
- ✔ Bis zu 5 Datenlieferanten
- ✔ Chat & 3 Webmeetings im Monat à 30 min
- ✔ Bis zu 20.000 SKUs insgesamt
- ✔ Excel, CSV
- ✔ Standard Datenmodell
- ✔ Kein Setup notwendig
- ✔ Zugang zur Knowlegdebase
Enterprise
- ✔ bis zu 10 Datenlieferanten
- ✔ Chat & 5 Webmeetings im Monat à 30 min
- ✔ eigene Key Account Manager
- ✔ unlimitierte Anzahl SKUs
- ✔ Excel, CSV, XML, API
- ✔ eigenes Datenmodell
- ✔ einmaliges Setup
- ✔ Strategieberatung
- ✔ Zugang zur Knowlegdebase
Monatlich kündbar
FAQs
Häufige Fragen – Antworten auf die wichtigsten Anliegen
Wie wird sicher gestellt, dass neue Datenquellen zuverlässig integriert werden?
Jede Regel und jede Logik muss nur einmal angelegt werden – anschließend ist sie eine bleibende Institution und arbeitet völlig automatisch. Neue Datenquellen (z. B. von Vorlieferanten) werden zuverlässig in die gewünschte Form gebracht. Außerdem können Attribute, die logisch sind, automatisch ergänzt werden. Kommt doch mal etwas völlig Neues, das die Logik nicht abbilden kann, wird einfach eine neue Regel ergänzt, die diesen Umstand abdeckt. Es muss nie wieder ein Datensatz manuell eingepflegt werden.
Warum sind saubere Daten so wichtig?
Unreine Daten sind Informationen, die zwar vorhanden, aber nicht einheitlich oder vergleichbar sind. Dies beinhaltet unterschiedliche Einheiten, Begriffe in anderen Sprachen oder oft auch Schreibfehler. Diese augenscheinlich marginalen Imperfektionen stehen dir bei modernen Anwendungen wie Produktempfehlungen, -vergleichen und -suchen im Wege. Die Bounce Rate von Kunden, die nicht finden können, was sie suchen, steigt. Wir lösen diese inkonsistenten und unreinen Daten durch eine intelligente Datenaufbereitung auf, und schafft eine saubere, normalisierte Datenstruktur.
Wie trägt die Technologie zur Verbesserung der Datenqualität bei?
Unsere Technologie lernt dazu und legt die Erkenntnisse in deiner Ontologie ab. So dienen Synonyme und Bezeichnungen aus anderen Sprachen zur Anreicherung und Verbesserung deiner Daten. Häufige Fehlschreibweisen können für Anwendungen – wie eine Produktsuche – wertvolle Informationen darstellen. Zusätzlich wird jeder Datenpunkt mit beliebigen Meta-Informationen versehen, die deine Prozesse bereichern. Dies kann z. B. eine Gewichtung für Sortierungen oder Vererbungen von Attributen sein.
Wieviel Aufwand habe ich?
Wir wissen, dass deine Zeit wertvoll ist. Deshalb haben wir einen effizienten Prozess entwickelt. Kein zusätzlicher Aufwand erforderlich – du kannst dich auf dein Kerngeschäft konzentrieren.